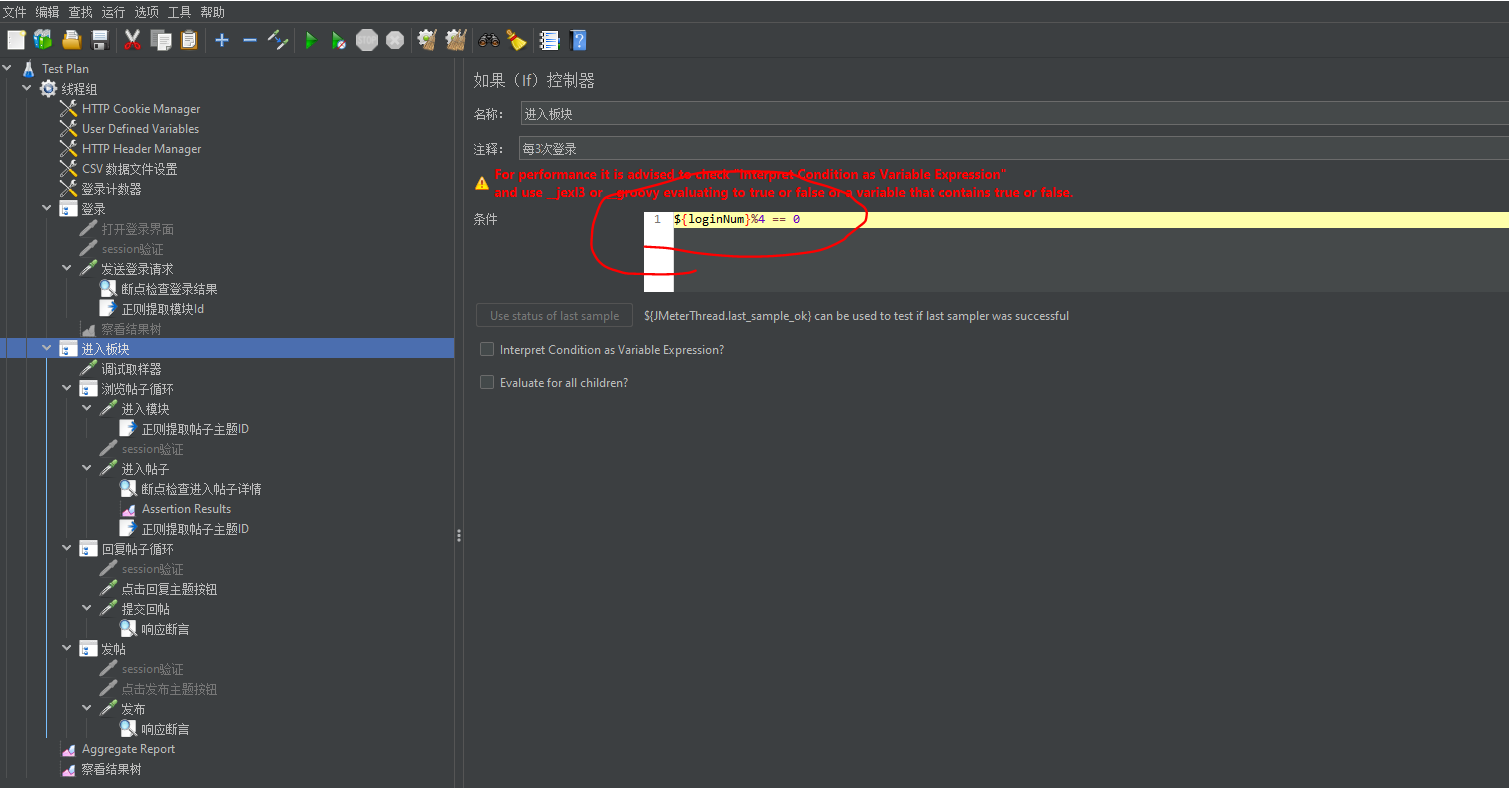
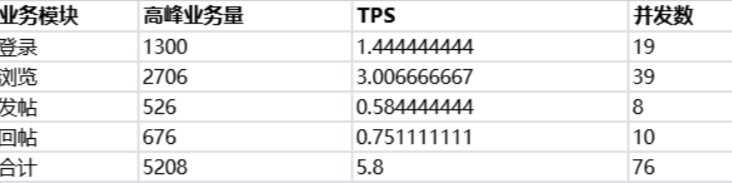
Concurrency Thread Group的介绍
- Concurrency Thread Group提供了用于配置多个线程计划的简化方法
- 该线程组目的是为了保持并发水平,意味着如果并发线程不够,则在运行线程中启动额外的线程
- 和Standard Thread Group不同,它不会预先创建所有线程,因此不会使用额外的内存
- 对于上篇讲到的Stepping Thread Group来说,Concurrency Thread Group是个更好的选择,因为它允许线程优雅地完成其工作
- Concurrency Thread Group提供了更好的用户行为模拟,因为它使您可以更轻松地控制测试的时间,并创建替换线程以防线程在过程中完成
Concurrency Thread Group参数讲解
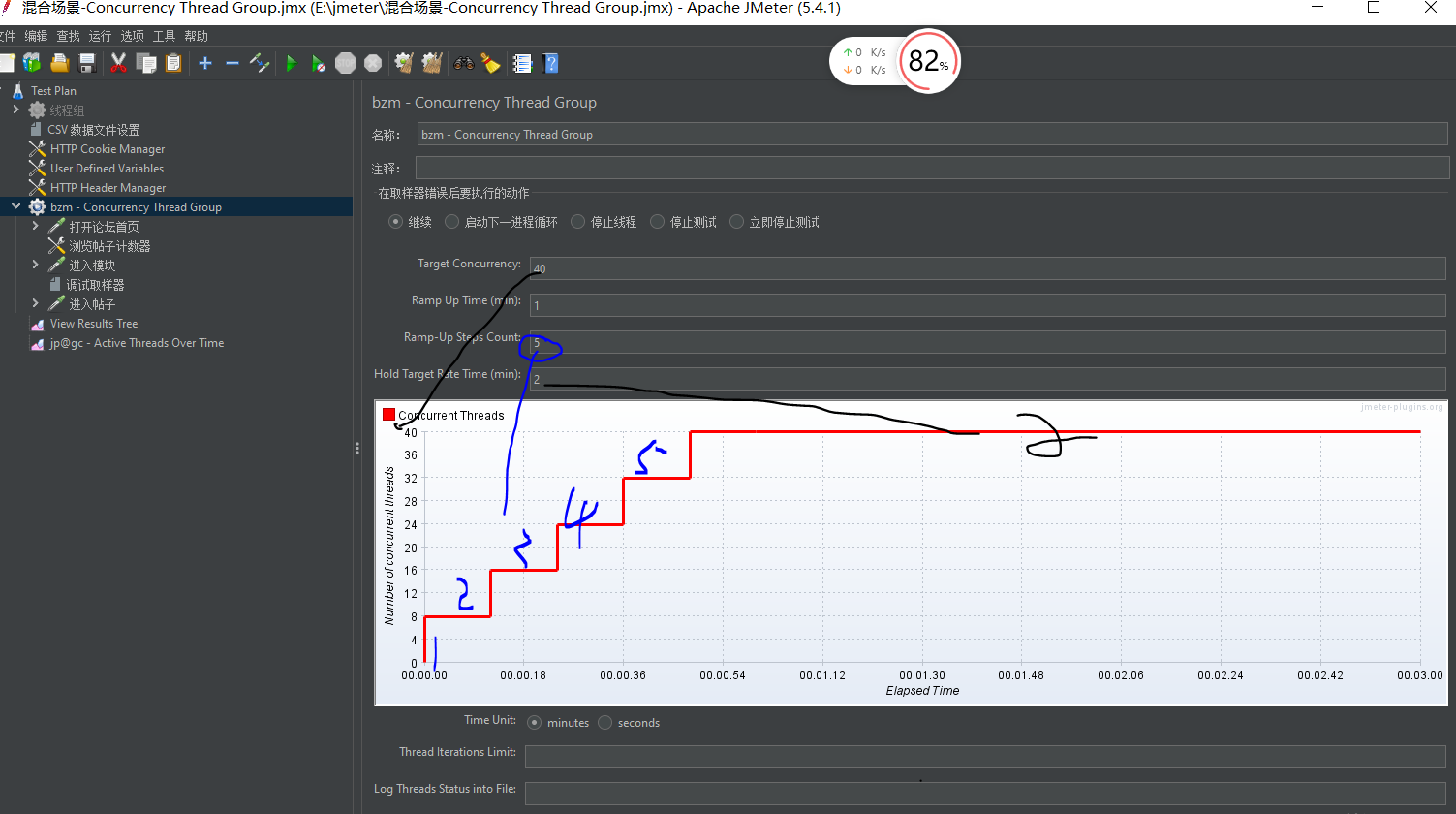
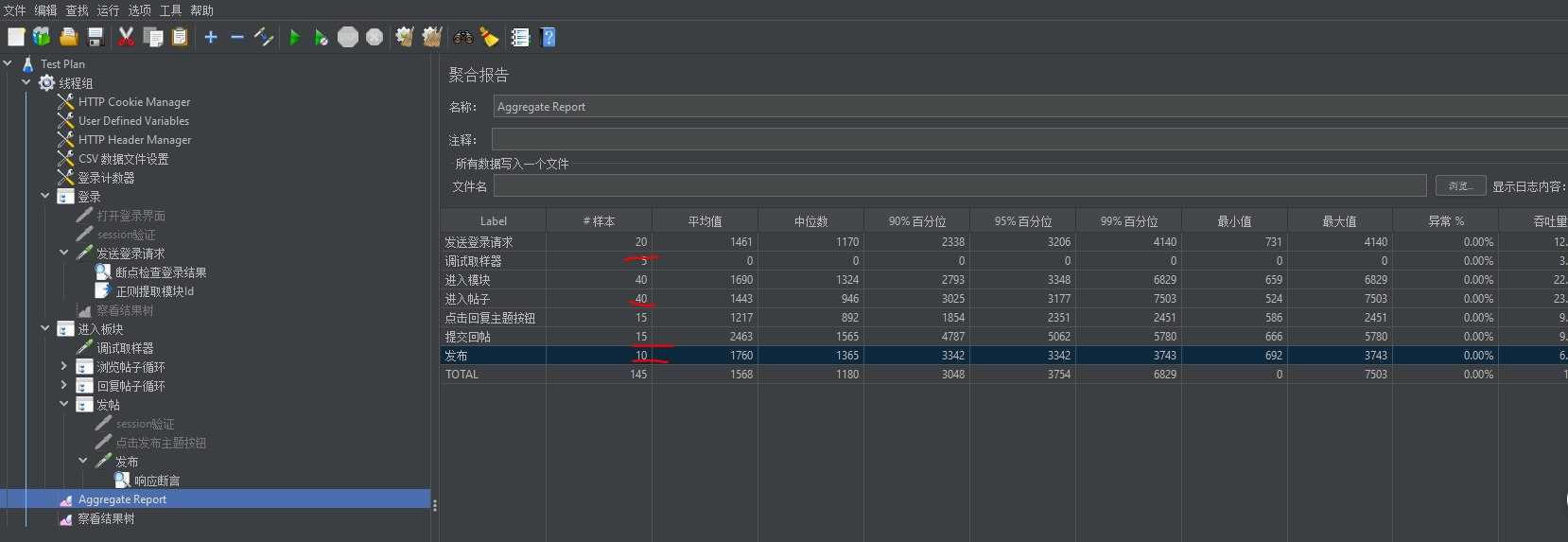
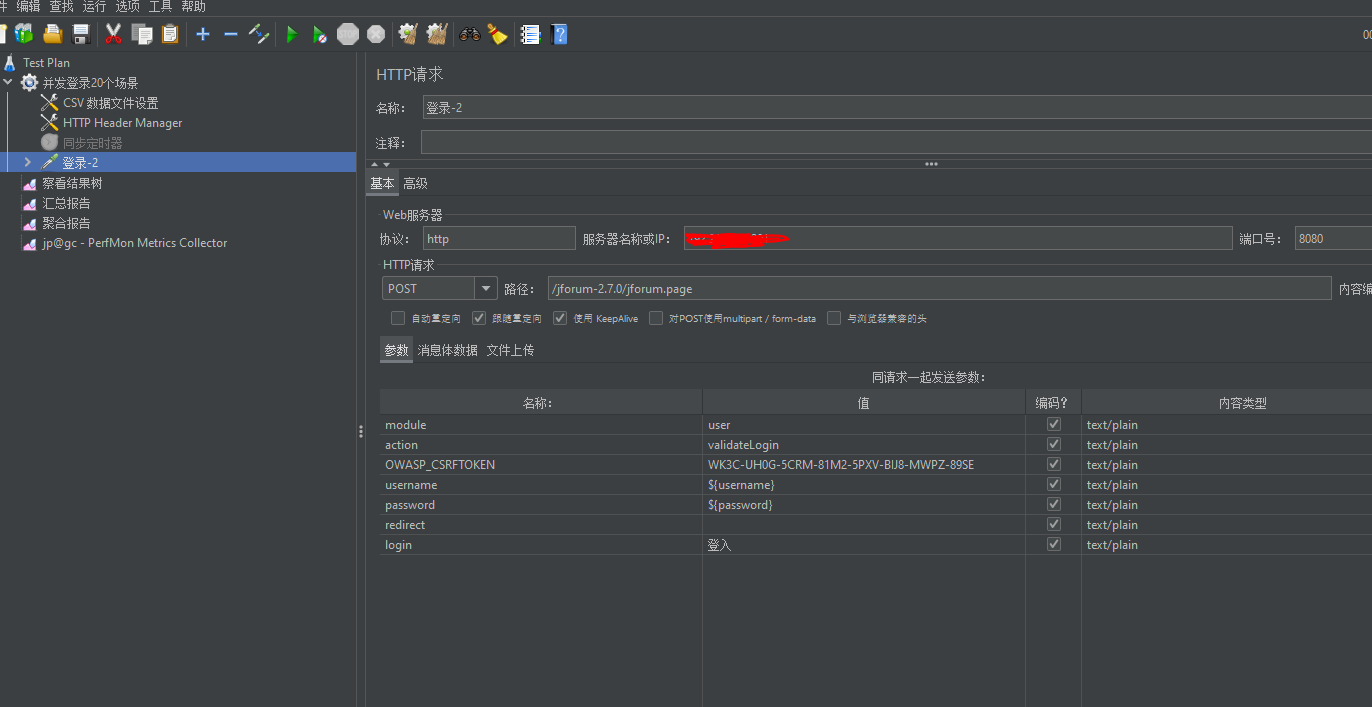
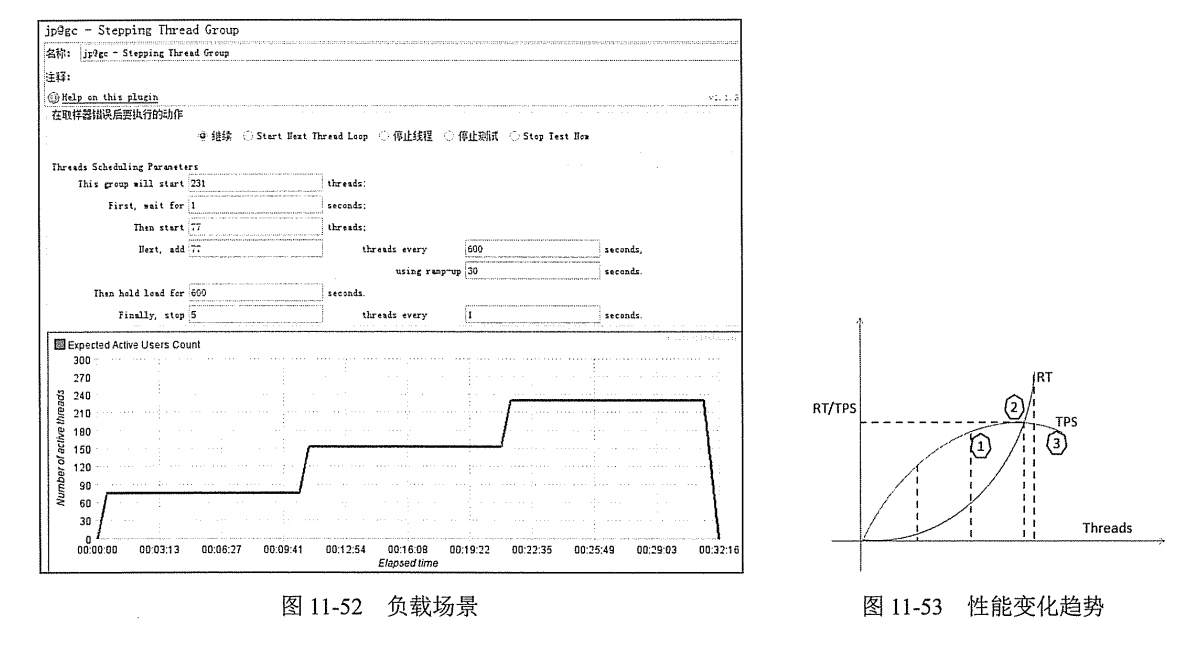
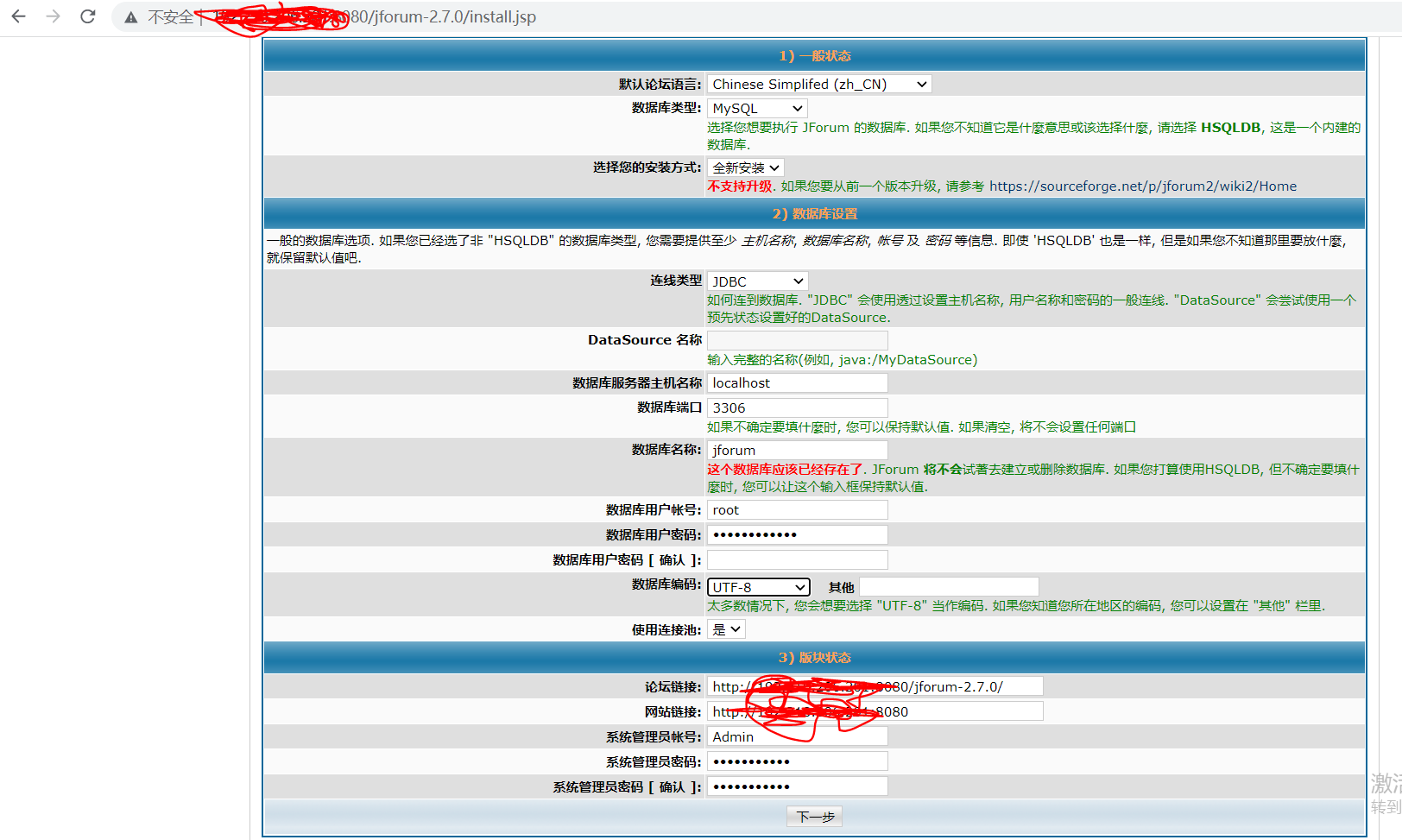
- Target Concurrency:目标并发(线程数),我设置为40
- Ramp Up Time:启动时间;若设置 1 min,则目标线程在1 imn内全部启动
- Ramp-Up Steps Count:阶梯次数;若设置 5 ,则目标线程在 1min 内分5次阶梯加压(启动线程);每次启动的线程数 = 目标线程数 / 阶梯次数 = 40 / 5 = 8
- Hold Target Rate Time:持续负载运行时间;若设置 2 ,则启动完所有线程后,持续负载运行 2 min,然后再结束
- Time Unit:时间单位(分钟或者秒)
- Thread Iterations Limit:线程迭代次数限制(循环次数);默认为空,理解成永远,如果运行时间到达Ramp Up Time + Hold Target Rate Time,则停止运行线程【不建议设置该值】
- Log Threads Status into File:将线程状态记录到文件中(将线程启动和线程停止事件保存为日志文件);
特别注意点
- Target Concurrency只是个期望值,实际不一定可以达到这个并发数,得看上面的配置【电脑性能、网络、内存、CPU等因素都会影响最终并发线程数】
- Jmeter会根据Target Concurrency的值和当前处于活动状态的线程数来判断当前并发线程数是否达到了Target Concurrency;若没有,则会不断启动线程,尽力让并发线程数达到Target Concurrency的值
Concurrency Thread Group和Stepping Thread Group的区别
官方说法
- Stepping Thread Group不提供设置启动延迟时间,阶梯增压过渡时间,阶梯释放过渡时间,但Concurrency Thread Group提供
- Stepping Thread Group可以阶梯释放线程,而Concurrency Thread Group是瞬时释放(具体看下面介绍)
- Stepping Thread Group设置了需要启动多少个线程就会严格执行,Concurrency Thread Group会尽力启动线程达到Target Concurrency值
通俗点理解
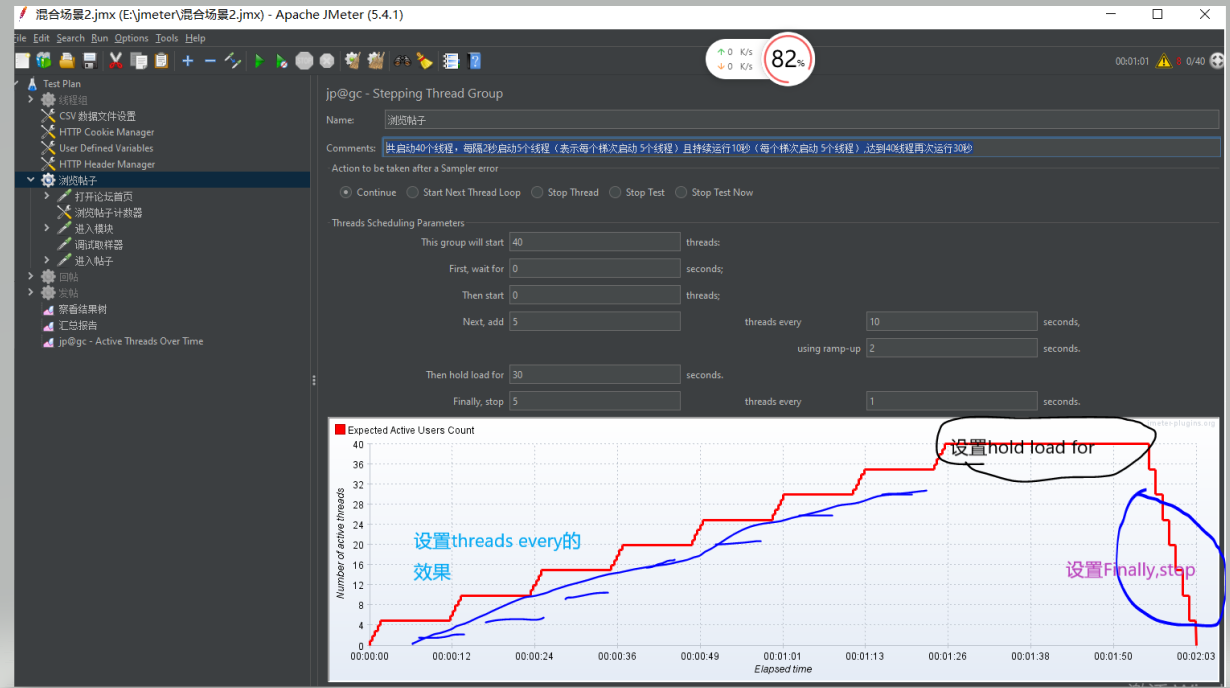
- Stepping Thread Group 是手动场景:测试过程,按照设定好的步骤执行
- Concurrency Thread Group 是目标场景:达到某个目标运行场景,测试过程不可控,动态变化
类比 LR
- Stepping Thread Group :设置并发用户数,持续时间等,每隔多少时间自动增加多少个用户
- Concurrency Thread Group:预设一个目标并发数,每隔一段时间增加一部分并发数,直到 TPS 达到目标并发数,然后持续运行一段时间
Concurrency Thread Group + Active Threads Over Time
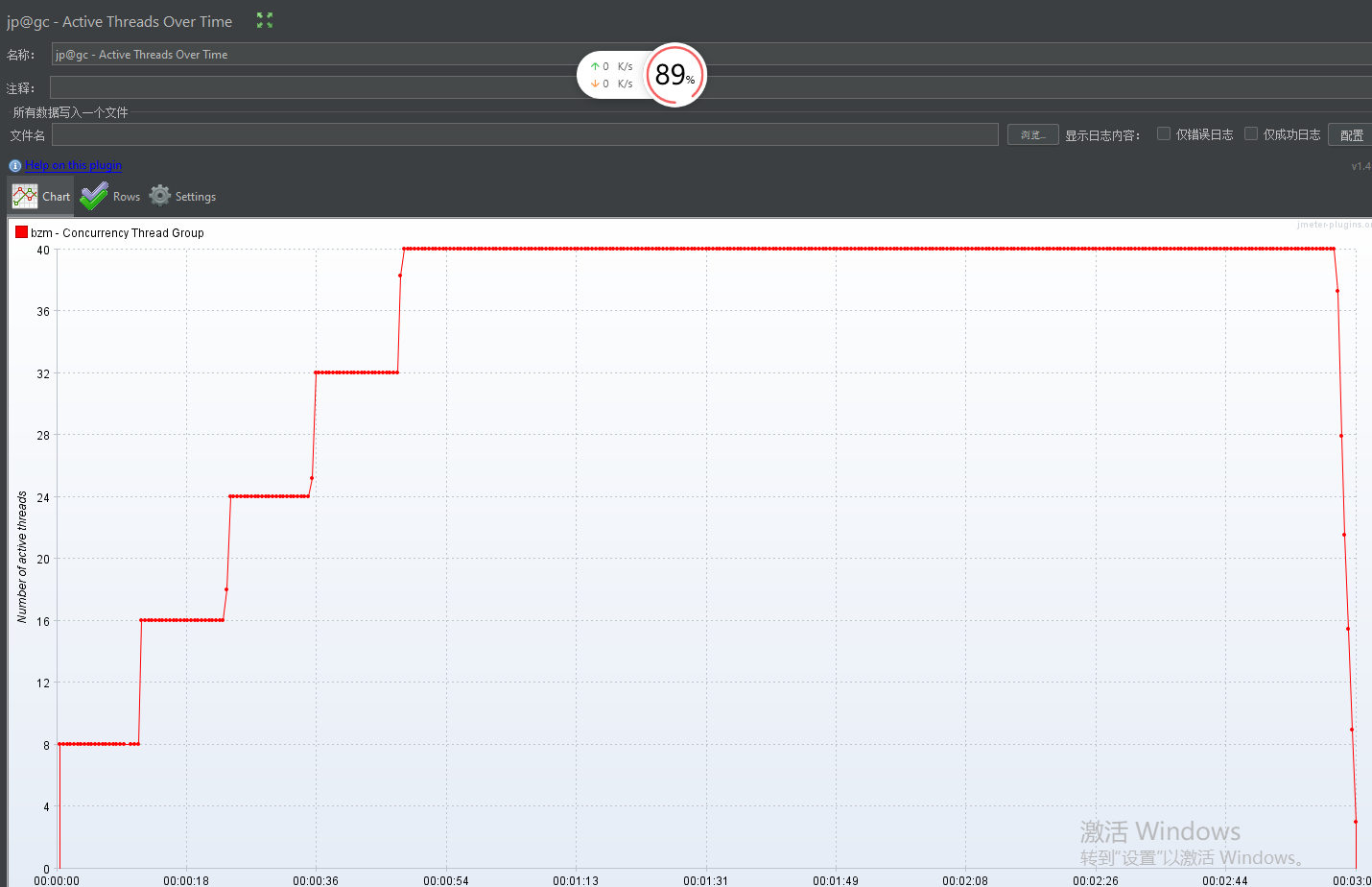
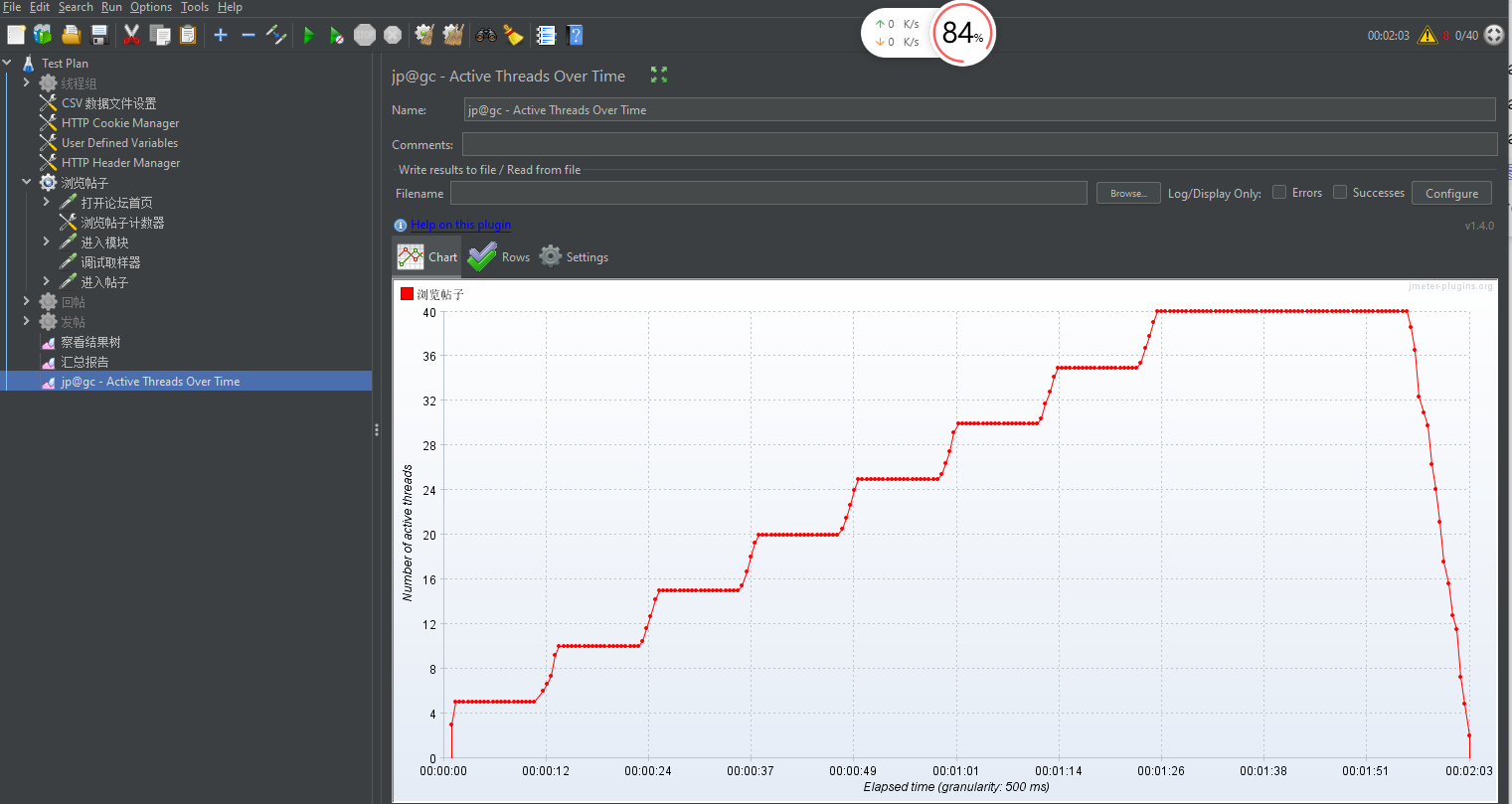
第一个关注点:阶梯增压过程
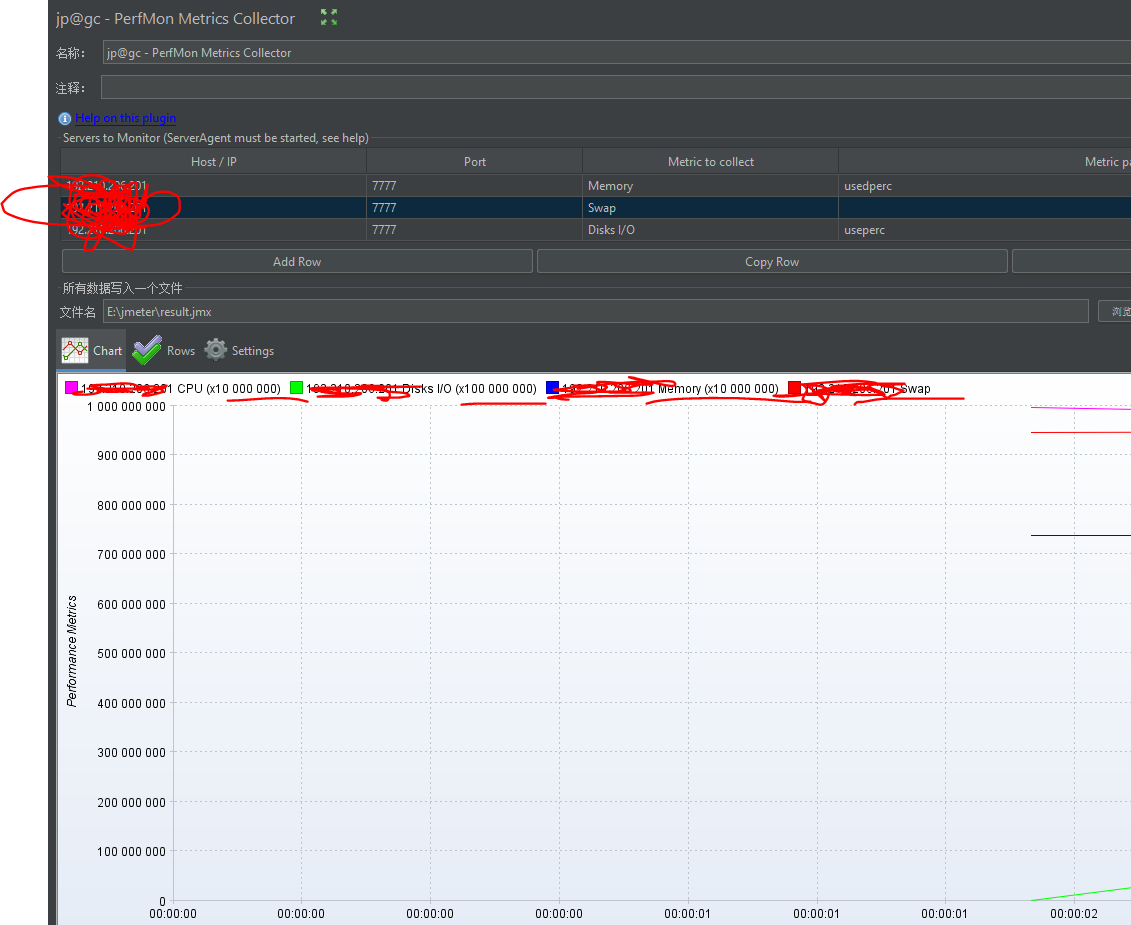
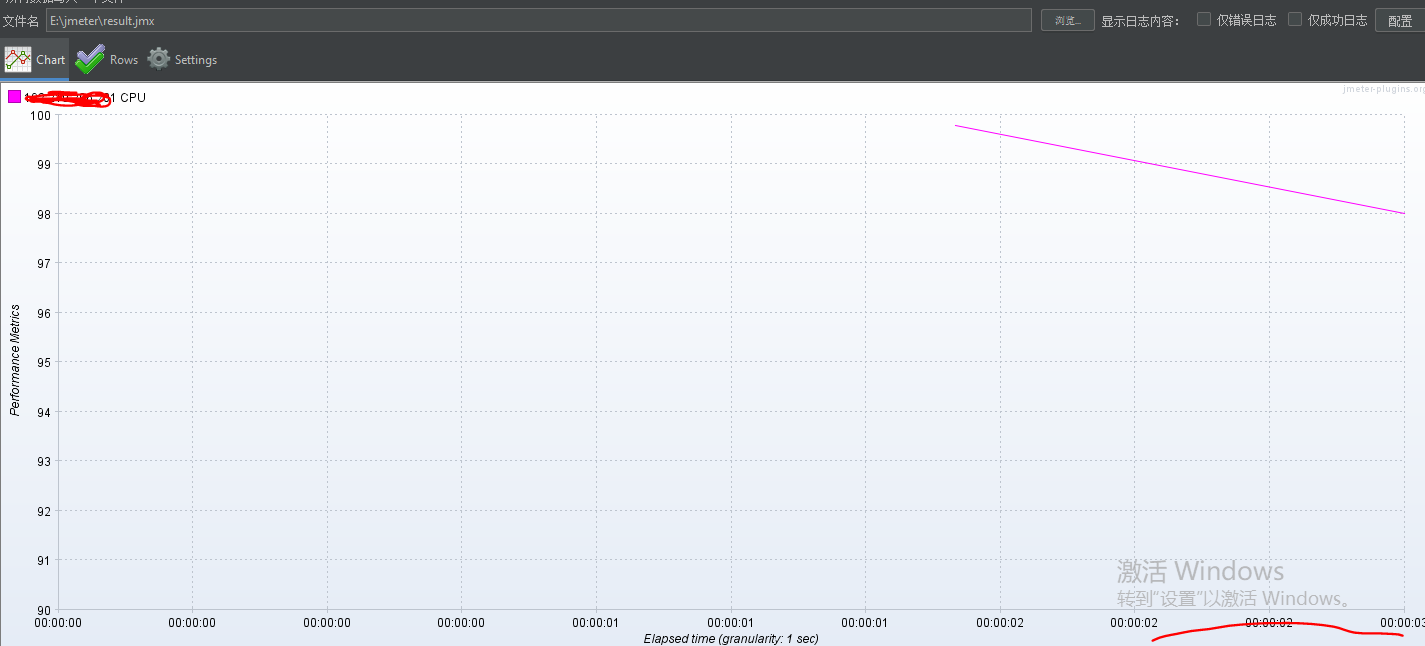
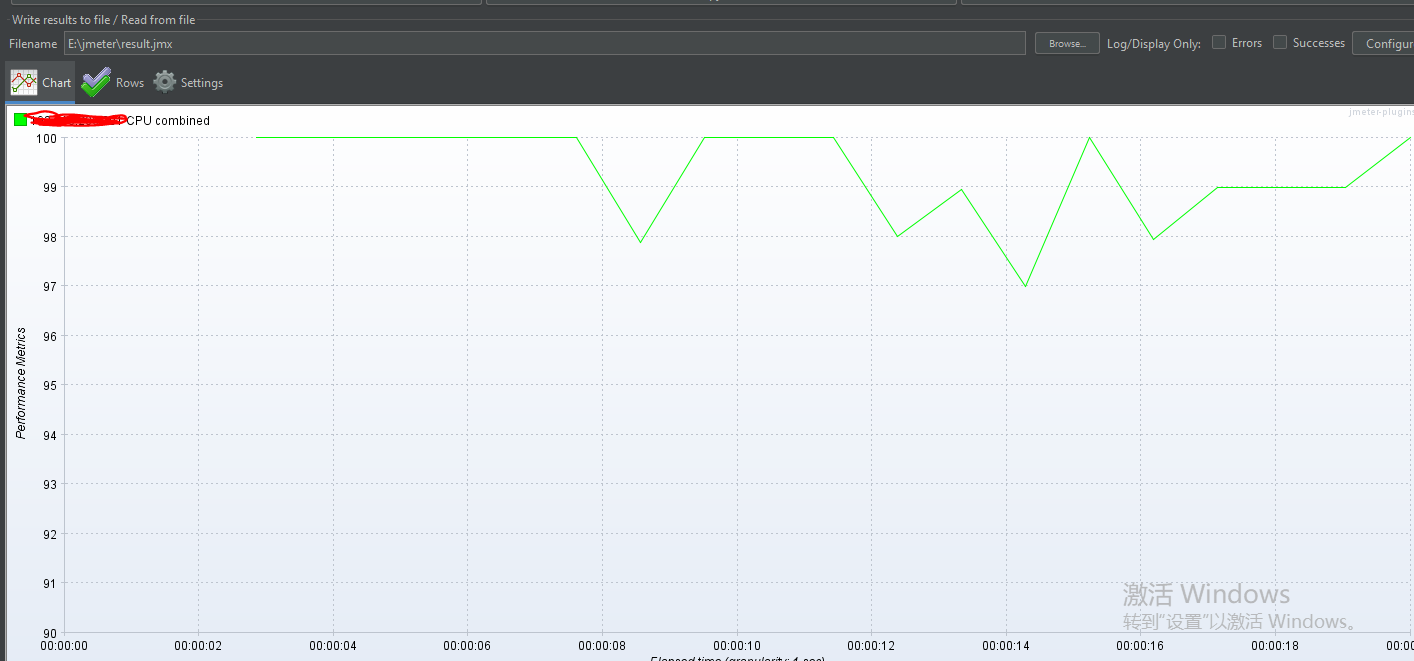
看Concurrency Thread Group负载预览图每次阶梯增压都是瞬时增压的,但是实际测试结果可以看到它也是有一个过渡期,并不是瞬时增压
第二个关注点:持续负载运行结束后,所有线程瞬时释放
- 从图最后可以看到,所有线程都是瞬时释放的
- 普通的线程组有三种状态:启动、运行、释放;而Concurrency Thread Group的线程可以理解成只有两种状态:启动、运行;因为线程都在极短的时间内就结束了
Concurrency Thread Group的扩展
- 当Concurrency Thread Group与Throughput Shaping Timer(吞吐量计时器)一起使用时,可以用tstFeedback 函数的调用来动态维护实现目标RPS所需的线程数
- 使用此方法时, 需要将Ramp Up Time 和 Ramp-Up Steps Count 置空
- 但要确保 Hold Target Rate Time ≥ Throughput Shaping Timer 时间表中指定的总持续时间值(Duration)
本文来自这里,强烈建议仔细学习此博主的jmeter系列文章