说明
- 本文章主要是学Flink 处理实时数据,使用zk+kafka搭建日志系统,python编写测试代码
- 本次服务器,采用的腾讯云服务器,使用的centos7 系统
- 本次的flink采用本地部署的方式,zk+kafka采用伪分布式
Flink特点
- 采用了基于操作符(Operator)的连续流模型,可以做到微秒级别的延迟。Flink最核心的数据结构是Stream,它代表一个运行在多分区上的并行流。在大数据场景中,经常用来对实时要求比较高的操作,比如实时处理。
如何选择Spark和Flink
对于以下场景,你可以选择 Spark:
- 数据量非常大而且逻辑复杂的批数据处理,并且对计算效率有较高要求(比如用大数据分析来构建推荐系统进行个性化推荐、广告定点投放等);
- 基于历史数据的交互式查询,要求响应较快;
- 基于实时数据流的数据处理,延迟性要求在在数百毫秒到数秒之间。
Spark完美满足这些场景的需求,而且它可以一站式解决这些问题,无需用别的数据处理平台。由于Flink是为了提升流处理而创建的平台,所以它适用于各种需要非常低延迟(微秒到毫秒级)的实时数据处理场景,比如实时日志报表分析。
而且Flink 用流处理去模拟批处理的思想,比Spark 用批处理去模拟流处理的思想扩展性更好具体参考
环境安装
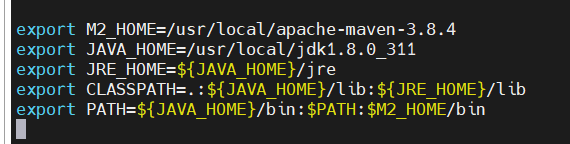
java
- flink安装的版本现在在官网为最新版本:V1.14.2,对java要求为8或者11
- 我之前已经搭建好了java刚好为 java8,此步省略
1 | [root@VM-24-13-centos ~]# java -version |
flink
- 常见部署模式分为:local本地部署(学习研究环节),集群模式有Standalone Cluster、Flink ON YARN、Mesos,Docker,Kubernetes等
- 本次采用本地部署,后续打算用本地三台虚拟机的方式学习(和hadoop一起)
1 | wget http://mirrors.aliyun.com/apache/flink/flink-1.14.2/flink-1.14.2-bin-scala_2.11.tgz |
- 启动flink
1 |
|
- flink一般都是8081端口,需要服务器防火墙打开,然后再腾讯云服务器再单独开启相应端口
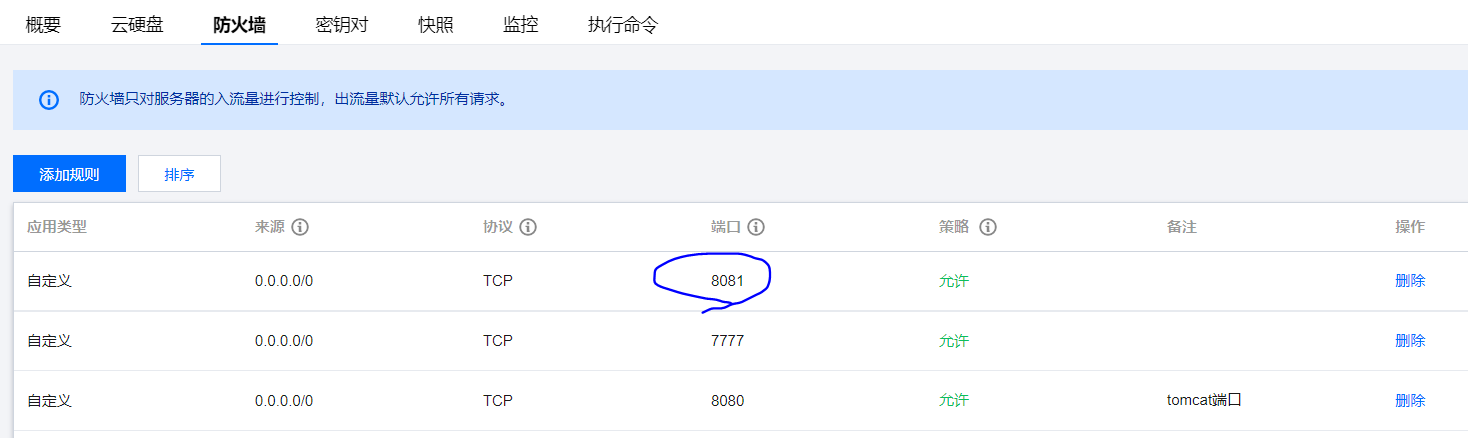
1 | [root@VM-24-13-centos flink-1.14.2]# firewall-cmd --zone=public --add-port=8081/tcp --permanent |
- 远程可以访问
kafka
- 一个分布式的、可分区的、可复制的消息中间件系统。kafka依赖于zookeeper
Zookeeper
- 注册中心,主要功能就是对中间件进行分布式通知/协调,比如对外部需要调用kafka,其实是通过调用zk进行协调访问。
- Master选举的方式是核心,可以看看zookeeper的原理和应用(非常详细透彻)和ZooKeeper原理及介绍,我暂时也没完全理解,zk有三个角色:leader(主)、follower(从)、observer(观察)
- 安装kafka之前,先安装zk,zk有三种部署方式:本地、伪分布式、完全分布式。本次打算采用伪分布式
1 | wget http://mirrors.aliyun.com/apache/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz |
- 复制1份zoo.cfg 配置文件,命名为 zoo.cfg,并做好配置,注意填入的ip要填入腾讯云的内外ip,之前填入公网ip一直启动失败
1 | cd zookeeper_01/conf |
- 复制zookeeper_01目录伪zookeeper_02,配置zoo.cfg
1 | cd /usr/local |
- 复制zookeeper_01目录伪zookeeper_03,配置zoo.cfg
1 | cd /usr/local |
- 修改zookeeper_01中conf目录下zoo.cfg文件
1 | dataDir=/usr/local/zookeeper_01/data |
- 修改zookeeper_02中conf目录下zoo.cfg文件
1 | dataDir=/usr/local/zookeeper_02/data |
- 修改zookeeper_03中conf目录下zoo.cfg文件
1 | dataDir=/usr/local/zookeeper_03/data |
- 分别启动zookeeper_01、zookeeper_02、zookeeper_03
1 | [root@VM-24-13-centos zookeeper_01]# bin/zkServer.sh start |
- 查看有三个
QuorumPeerMain进程
1 |
|
- 查看每个zk启动的模式,发现zookeeper_03的model为leader
1 |
|
kafka介绍
- kafka是Apache组织下的一个开源系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop平台的数据分析、低时延的实时系统、storm/spark流式处理引擎等。kafka现在它已被多家大型公司作为多种类型的数据管道和消息系统使用。
- 来源于这里
kafka角色
| 角色 | 说明 |
|---|---|
| Broker | Kafka服务器,无论是单台Kafka还是集群,被统一叫做Broker |
| Producer | 指消息的生产者,负责发布消息到kafka broker |
| Consumer | 指消息的消费者,从kafka broker拉取数据,并消费这些已发布的消息。Kafka发布消息通常有两种模式:**队列模式(queuing)和发布/订阅模式(publish-subscribe)**。在队列模式下,只有一个消费组,而这个消费组有多个消费者,一条消息只能被这个消费组中的一个消费者所消费;而在发布/订阅模式下,可有多个消费组,每个消费组只有一个消费者,同一条消息可被多个消费组消费 |
| Topic | 主题,用于建立生产者和消费者之间的订阅关系,生产者将消息发送到指定的Topic,然后消费者再从该Topic下去取消息 |
| Partition | 消息分区,一个Topic下面会有多个Partition,每个Partition都是一个有序队列,Partition中的每条消息都会被分配一个有序的id。 |
| Consumer Group | 消费者组,可以给每个Consumer指定消费组,若不指定消费者组,则属于默认的group |
| Message | 消息,通信的基本单位,每个producer可以向一个topic发布一些消息。 |
kafka工作流程
生产者定期向主题发送消息。
Kafka broker将所有消息存储在为该特定主题配置的分区中。它确保消息在分区之间平等共享。如果生产者发送两个消息,并且有两个分区,则Kafka将在第一个分区中存储一个消息,在第二个分区中存储第二个消息。
消费者订阅一个特定的主题。一旦消费者订阅了一个主题,Kafka将向消费者提供该主题的当前偏移量,并将偏移量保存在ZooKeeper中。
消费者将定期请求Kafka新消息。
一旦Kafka收到来自生产者的消息,它会将这些消息转发给消费者。消费者将收到消息并处理它。
一旦消息被处理,消费者将向Kafka broker发送确认。
一旦Kafka收到确认,它会将偏移量更改为新值,并在ZooKeeper中进行更新。由于ZooKeeper中保留了偏移量,因此即使在服务器出现故障时,消费者也可以正确读取下一条消息
kafka拓扑架构
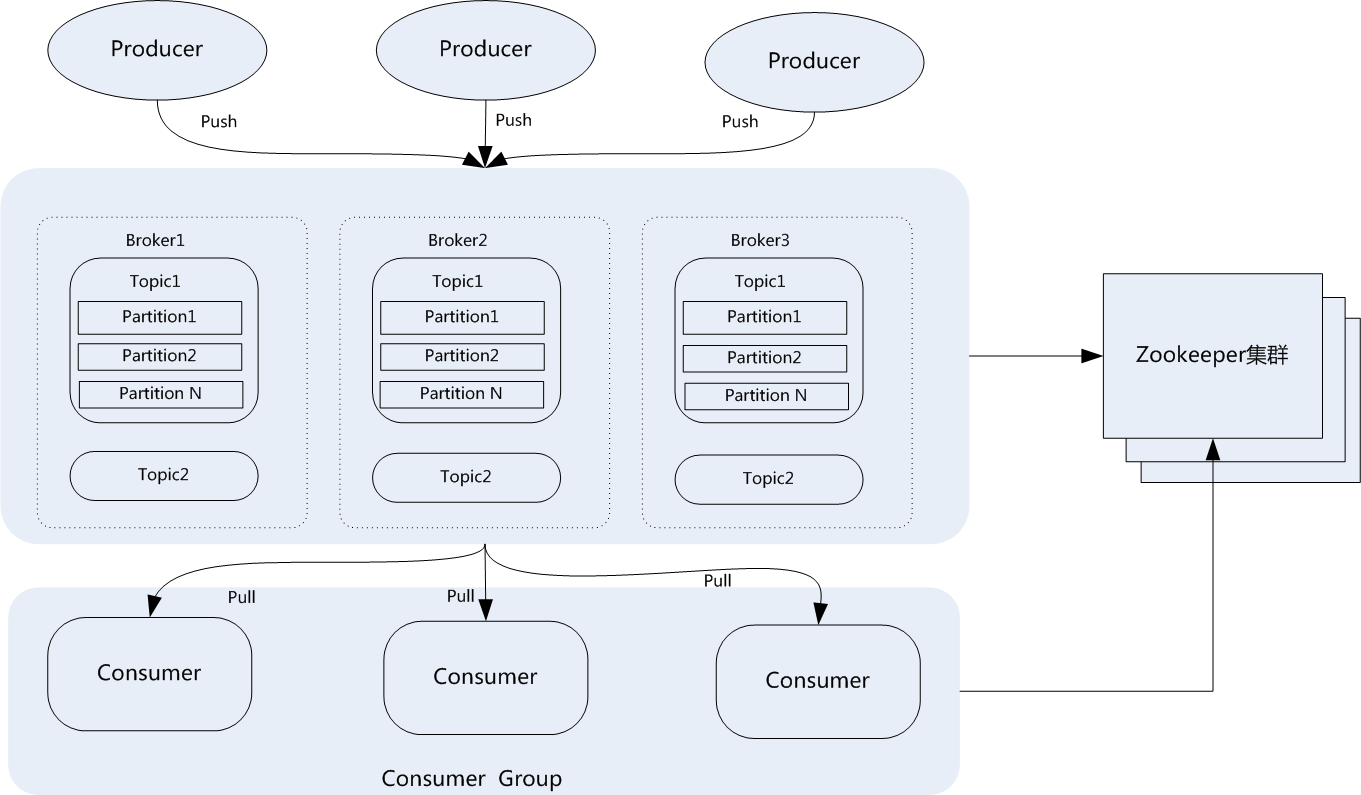
- 一个典型的Kafka集群包含若干Producer,若干broker、若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。典型架构如下图所示
安装配置kafka
1 | wget --no-check-certificate https://dlcdn.apache.org/kafka/3.0.0/kafka_2.12-3.0.0.tgz |
- 复制server.properties命名为server1.properties,配置如下
1 | cd kafka/config |
- 复制server1.properties命名为server2.properties,配置如下
1 | cp server.properties1 server2.properties |
- 复制server1.properties命名为server3.properties,配置如下
1 | cp server.properties1 server3.properties |
- 修改
bin目录下的kafka-server-start.sh文件,将初始堆的大小(-Xms)设置小一些,不然启动报错
1 | export KAFKA_HEAP_OPTS="-Xmx1024M -Xms128M" |
- 启动kafka。切记先要启动zk
1 |
|
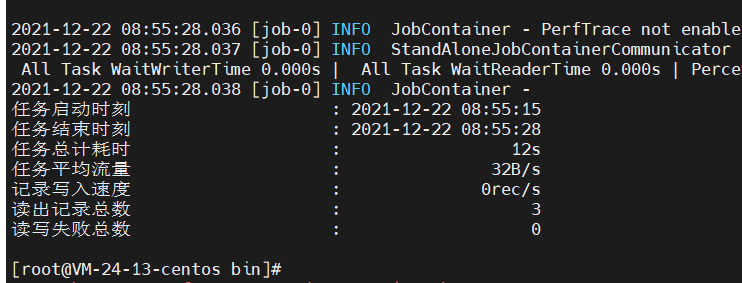
- 查看kafka和flink是否启动
1 | [root@VM-24-13-centos ~]# jps |
python3
- 服务器现在默认用的python2.7,现在升级为python3
1 | 安装依赖文件 |
- 备份python2
1 | mv /usr/bin/python /usr/bin/python.bak |
- 创建软链接
1 | ln -s /usr/local/python3/bin/python3 /usr/bin/python |
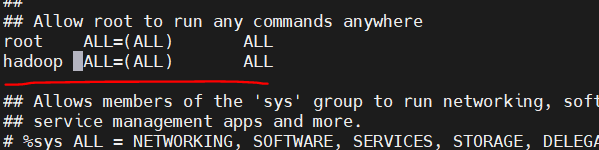
- 修改yum配置文件。由于执行CentOS的yum命令需要使用自带的python2的版本,所以需要做两处修改
1 | vi /usr/bin/yum |
- 查看python3版本
1 | [root@VM-24-13-centos local]# python --version |
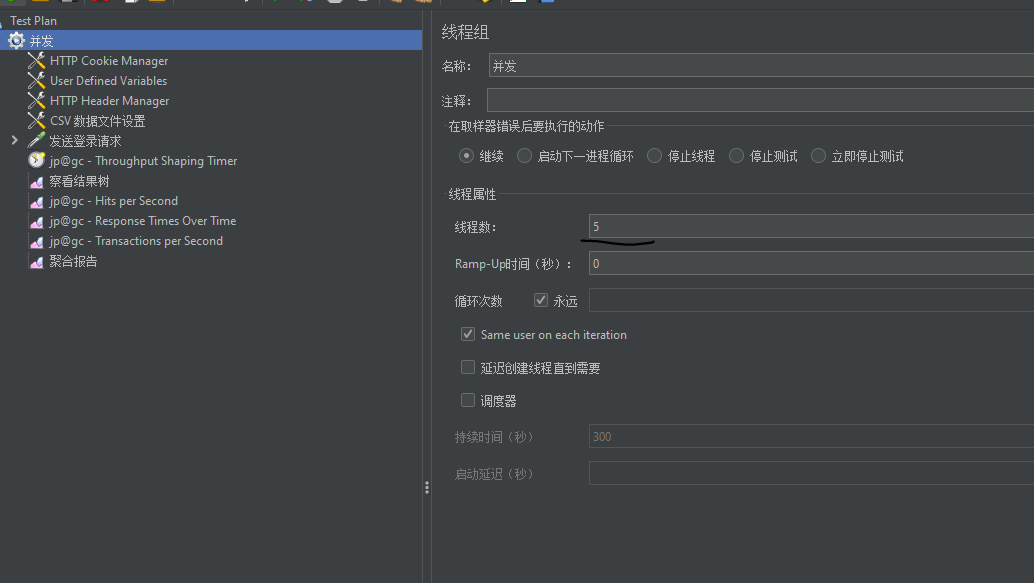
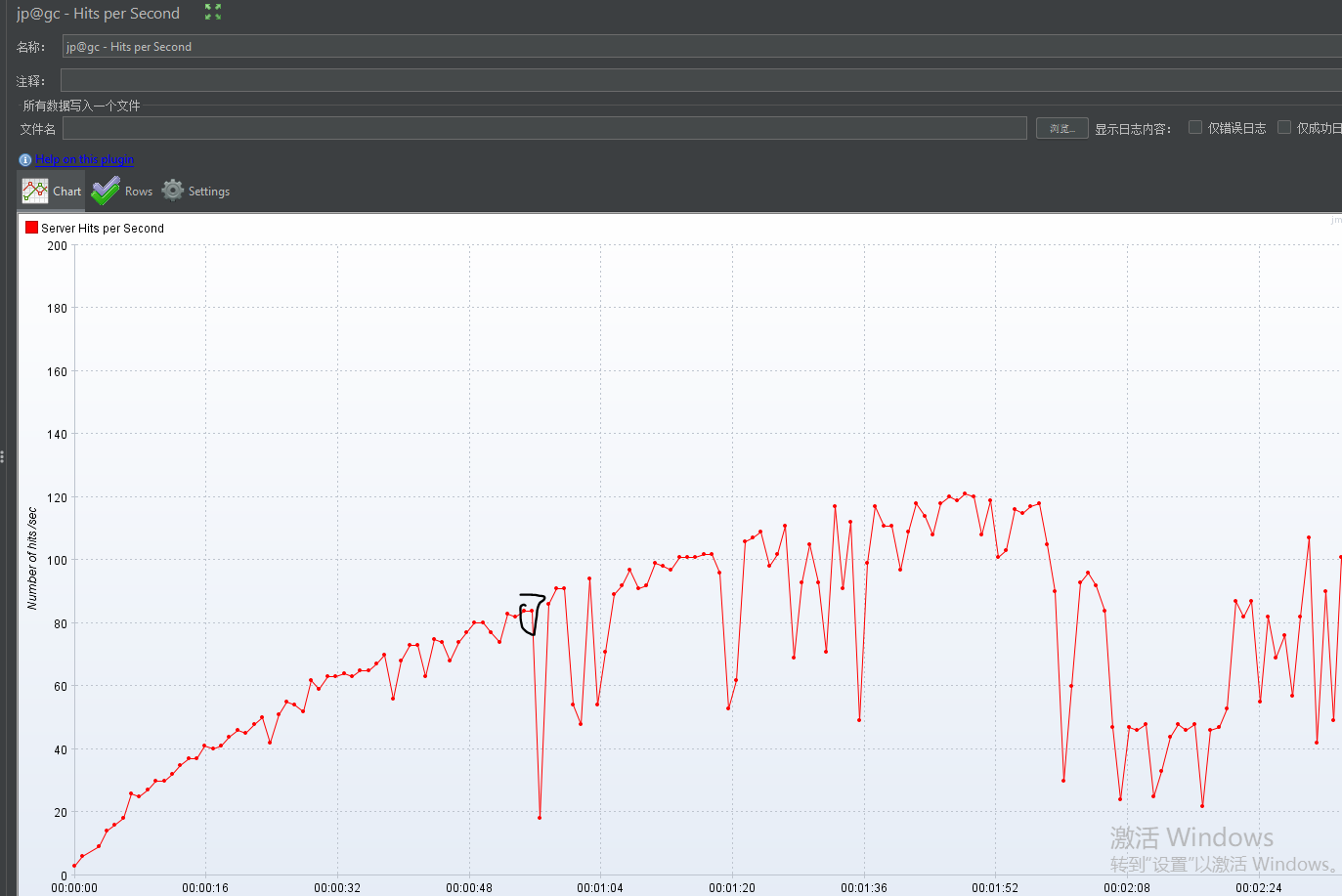
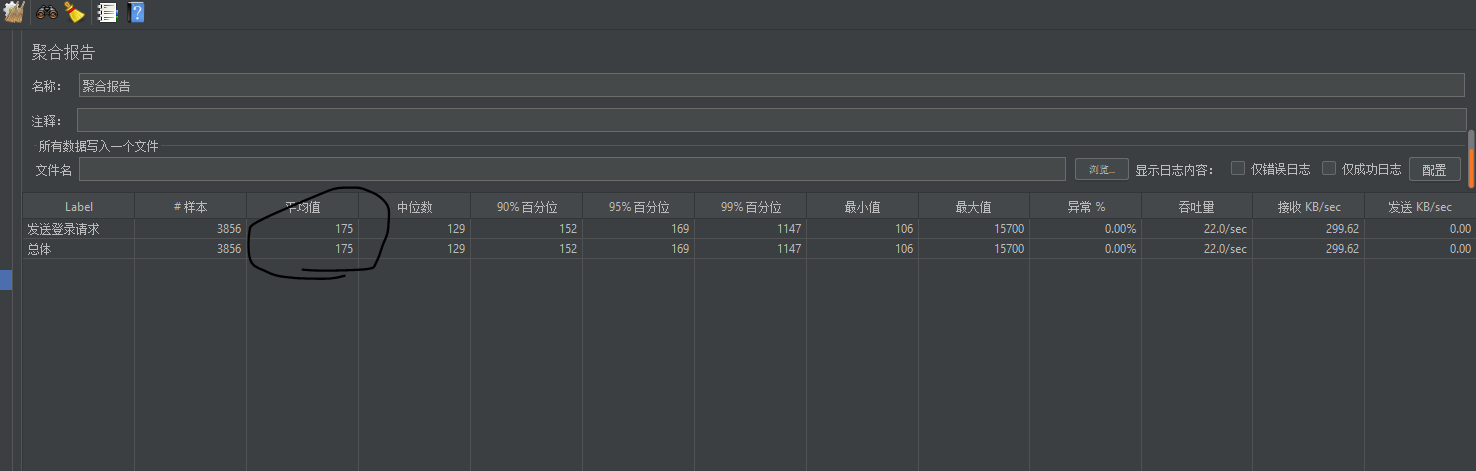
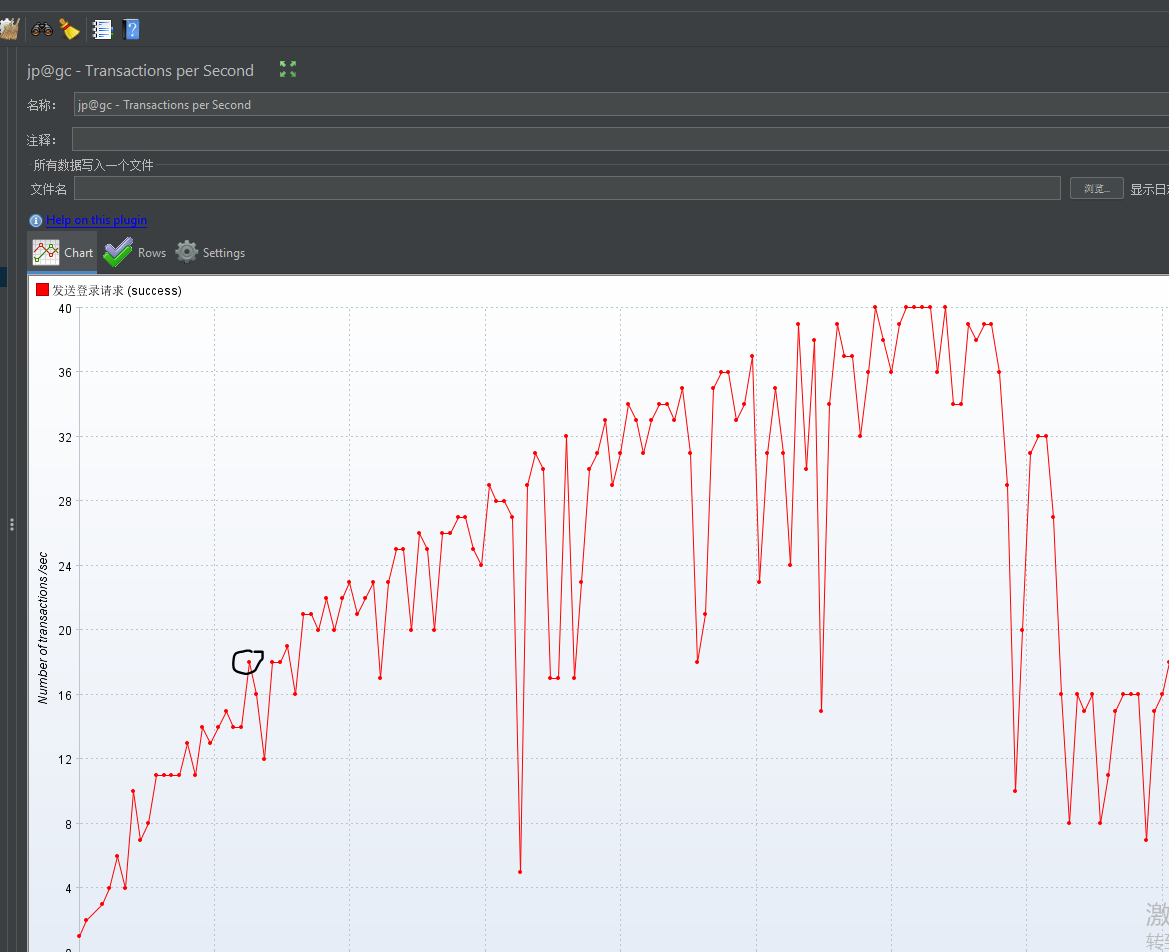
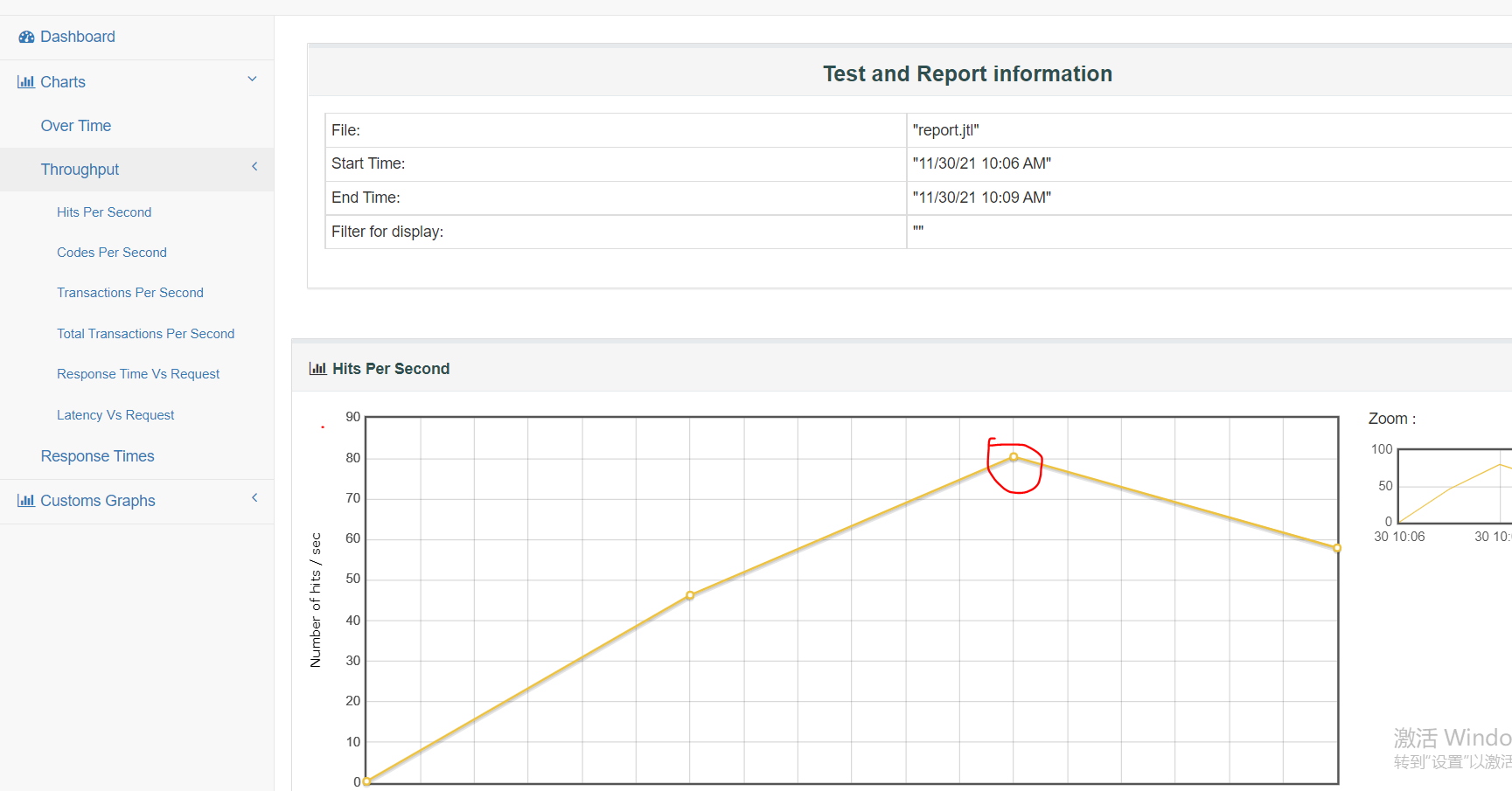
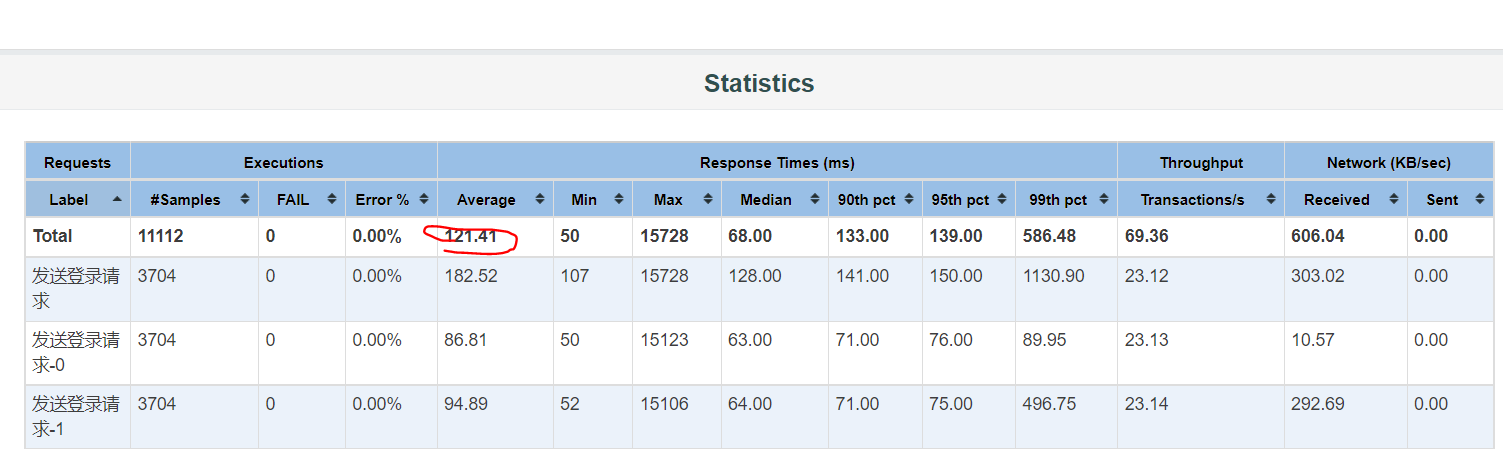
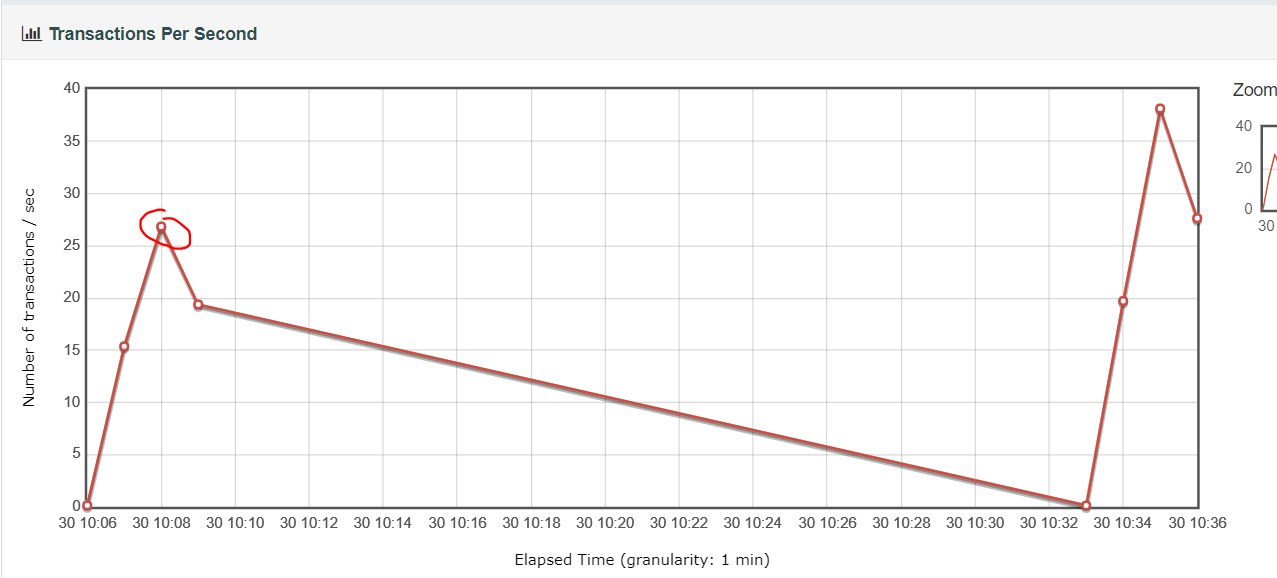
测试过程
- 暂时放弃,服务器内存不足,在一台机器上部署分布式配置不够