大数据项目开发概览
一个完整的大数据项目架构可以分为数据采集层、数据存储层、数据计算层、数据接入层、数据应用层和基础服务层,如下图所示:
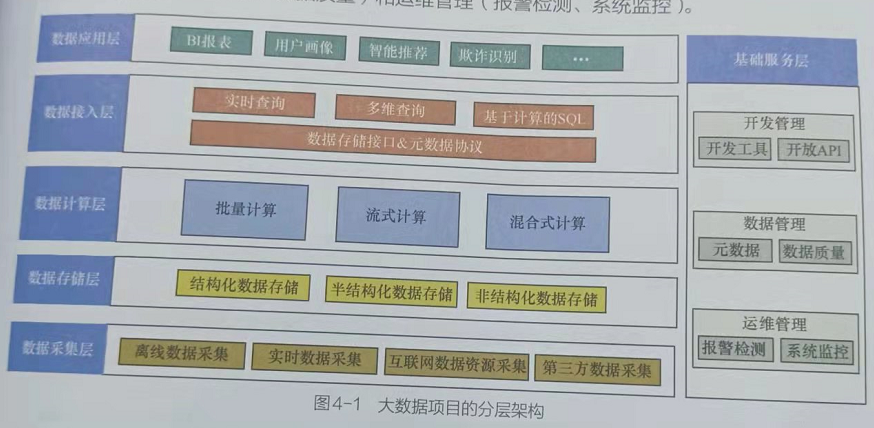
数据的采集和存储
数据采集方式主要有:
网络数据采集
服务端日志采集
客户端日志采集
服务端日志采集
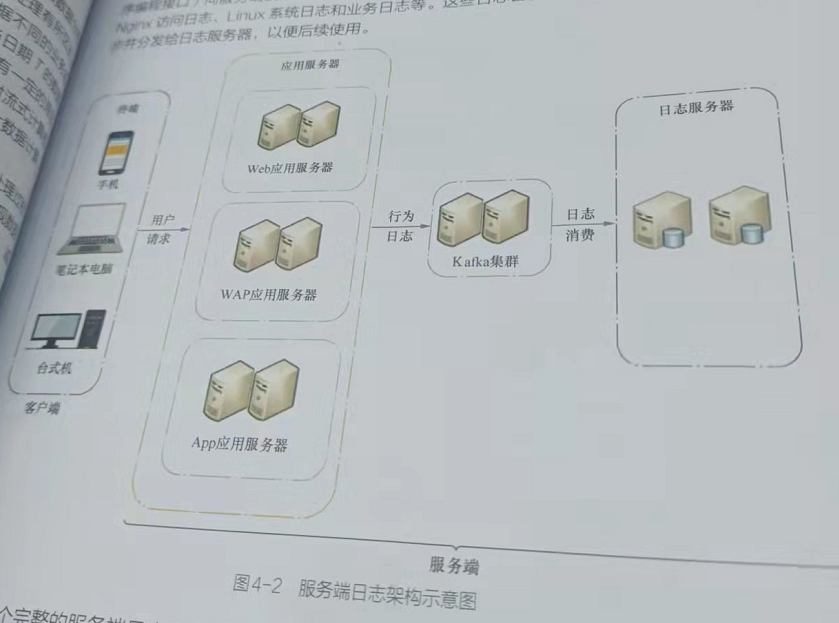
- 服务端日志是重要的数据来源,它可以支持业务问题排查、业务数据分析等。下图是常见的服务端日志架构。客户端通过API( Application Programming Interface,应用程序编程接口)向服务端发送请求,服务端会在服务器本地记录日志文件。日志文件可能包括访问日志、Lnux系统日志和业务日志等。这些日志会被服务端日志采集服务收集、同步发给日志服务器,以便后续使用。
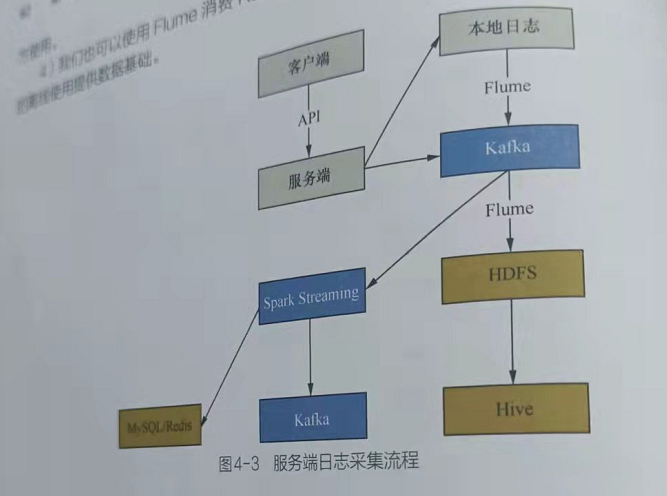
一个完整的服务端日志采集流程如图4-3所示。
在客户端向服务端发送请求后,服务端会在服务器本地记录请求日志或业务日志。此外,服务端会通过服务直接向Kafka推送日志。
服务器的本地日志在写入的同时,还会通过Flume等工具进行持续收集,并推送到 Kafka集群中指定的主题。在收集、推送的过程中,会进行一些日志数据处理工作,如请求头信息解析、接口参数提取和日志信息格式化等。
我们可以使用SparkStreaming实时消费处理Kafka消息,并将处理好的数据写入指定的数据库中,如MySQL、Redis等。此种方式可以提供实时的服务端日志应用,如错误日志监控报警等。对于Spark Streaming处理完的数据,将继续推送到Kafka,供其他业务
我们也可以使用flume消费kafka的消息,并将处理号的数据写入HDFS,为后续的离线使用提供基础数据
客户端日志采集
移动端分类
移动端分为两种:
- Native App:原生应用程序。也就是基于智能手机系统的原生程式编写运行的应用程序,比如Android,IOS等
- Hybrid App:混合应用程序。原生应用程序嵌入h5的方式
采集方式
- 浏览器页面的日志采集。如采集Hybrid App中h5浏览器
- 浏览量PV
- 访问量UV
- 移动端客户端日志的采集。如采集Native App
- 埋点SDK
数据同步
- 数据仓库的特性之一是集成,即首先把未经过加工处理的、不同来源的、不同形式的数据同步到ODS层,一般情况下,这些ODS层数据包括日志数据和业务DB数据。对于业务DB数据而言(比如存储在MySQL中),将数据采集并导入到数仓中(通常是Hive或者MaxCompute)是非常重要的一个环节。
- 针对不同数据类型和业务场景,我们可以选择不同的数据同步方式:
- 直连同步
- 数据文件同步
- 数据库日志解析同步
直连同步
- 直连同步是指通过定义好的规范接口API和基于动态链接库的方式直接连接业务库
- 直连同步的方式配置十分简单,很容易上手操作,比较适合操作型业务系统的数据同步,但是会存在随着业务规模的增长,数据同步花费的时间会越来越长、连数据库查询数据,对数据库影响非常大,容易造成慢查询,可能会影响业务线上的正常服务

- 第五章 数据仓库实例,就是采用这种方式
数据文件同步
- 对文件进行格式约定,直接从源系统生成数据(mysql,oracle,DB2等)的文件,通过FTP服务器传输到目标系统,最终加载到目标系统中。
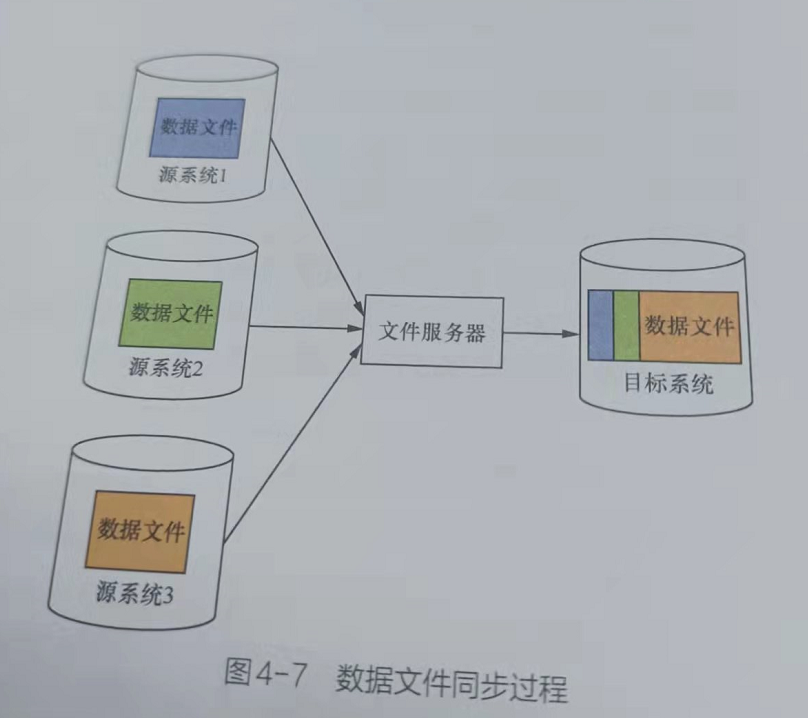
- 通过文件服务进行上传、下载,可能出现丢包或出现错误。可以加一些校验机制
数据库日志解析同步
- 数据库日志解析的同步方式可以实现实时与准实时的同步,延迟可以控制在毫秒级别的,其最大的优势就是性能好、效率高,不会对源数据库造成影响,目前,从业务系统到数据仓库中的实时增量同步,广泛采取这种方式。当然,这种方式也会存在一些问题,比如批量补数时造成大量数据更新,日志解析会处理较慢,造成数据延迟。除此之外,这种方式比较复杂,投入也较大,因为需要一个实时的抽取系统去抽取并解析日志
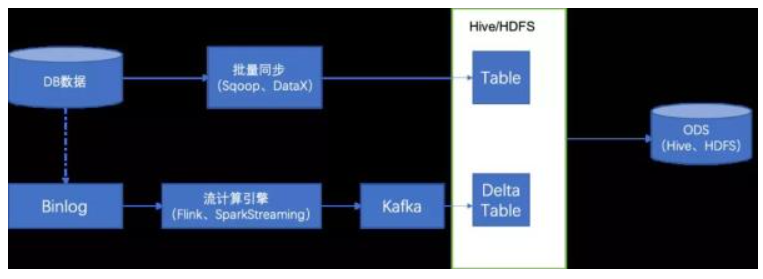
大数据存储
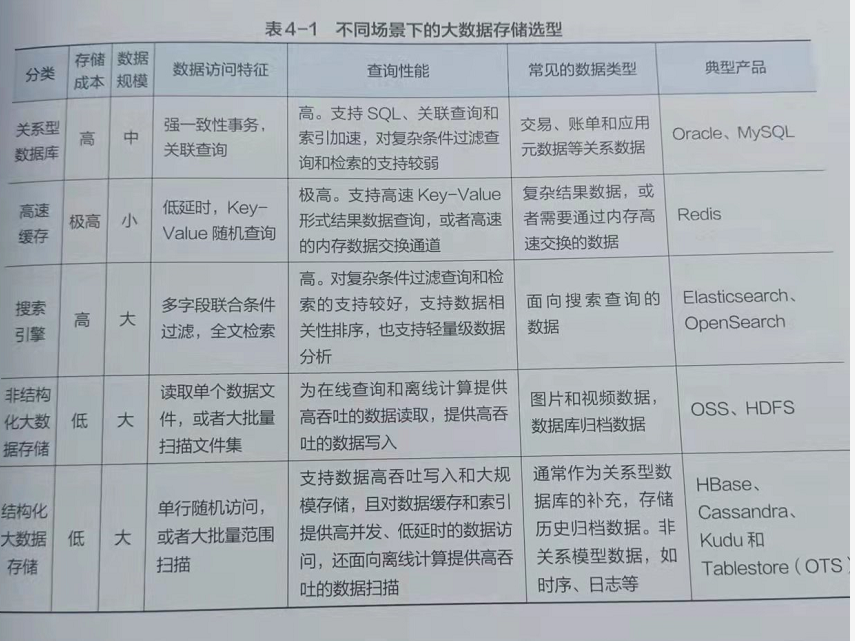
对于大数据存储选项,需要从存储成本、数据规模、数据访问特性和查询性能等方面进行考虑,下图列举了不同场景大数据存储选型。
大数据计算
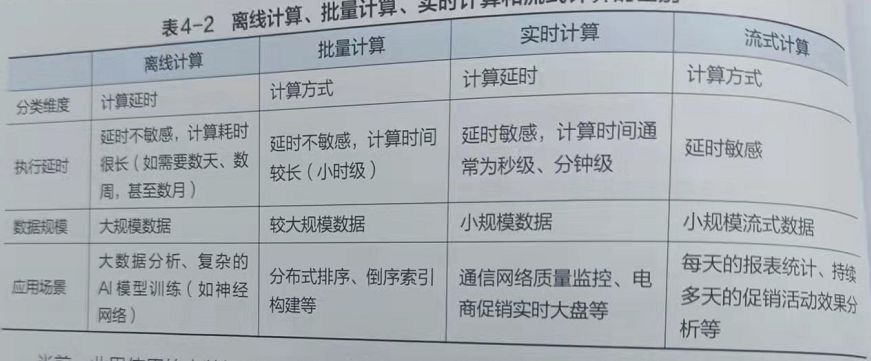
- 一般分为离线计算、批量计算、实时计算和流式计算,业界一般都使用离线计算和实时计算,下图是各个计算方式的区别
离线计算
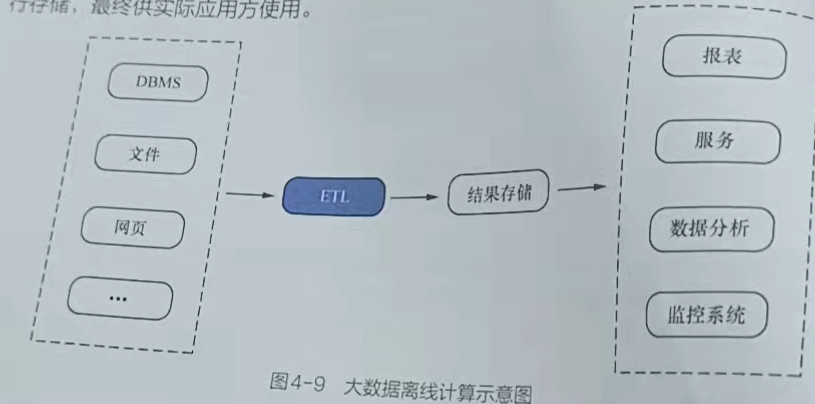
- 离线计算使用的多数场景是周期(小时、天,月)性执行一个job任务,离线计算应用中常用的是离线ETL的处理。如MapReduce就是一个离线的计算框架,下图举例说明了离线计算工作流
- 离线计算需要上下游各组件合作,一般会由多个任务单元构成(HiveQL,shell,Shell和MapReduce等),多个单元由很强的依赖关系
实时计算
- 对数据计算要求较高,如实时的ETL,实时监控等,延时一般为毫秒级别,目前笔比较流行的实时框架有
Spark Streaming和Flink - 下图展示了一个大数据计算平台架构,其中包含离线计算和实时计算
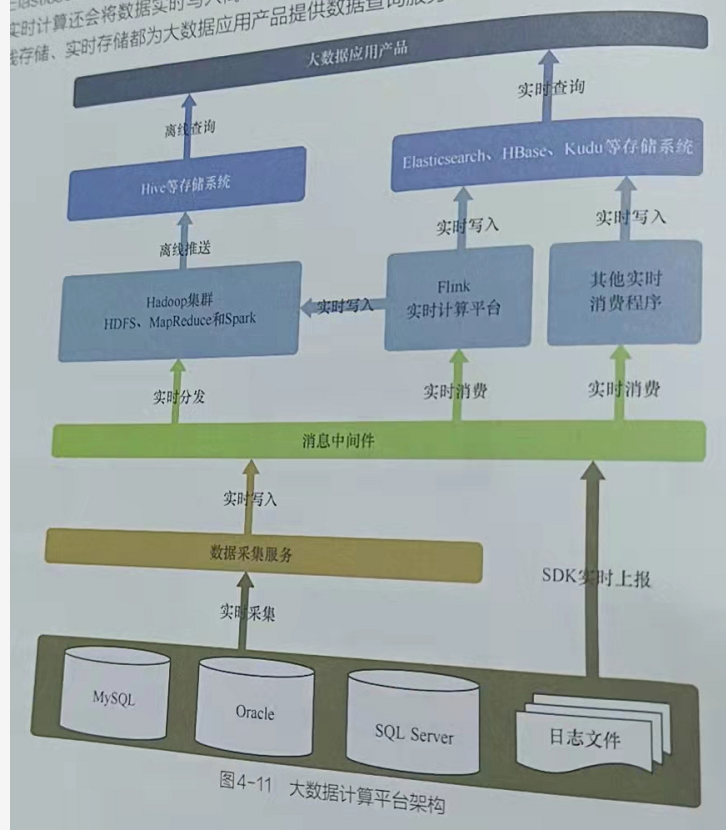
大数据监控
在大数据进行采集、存储和处理后,下面就是项目的上线和日常运行。在运行过程中监控和报警就非常重要
数据监控
一些常见的监控内容:
- 以时间维度对数据记录进行监控。比如某个时间段出现明显波动
- 对数据的NULL和0值进行监控
- 对数据的值域进行监控。如对数据中某字段出现合理域值以外的值
- 对数据的重复度进行监控。如电商业务的交易记录出现重复等
运维监控
- 在当前大数据项目中,使用服务器集群方式支撑业务已经成为常态,开发自动化运维监控系统非常重要。
- 监控常见的cpu,men,io,tps,对大数据生态系统进行监控,如zookeeper节点可用性,yarn资源空闲情况、kafka消息堆积情况,以及spark job完成进度等
- 其他的一些监控,如端口,nginx的延迟
大数据项目开发案例
- 数据分析平台是一类重要的大数据应用,广泛应用于互联网金融、银行、电子商务和在线教育等领域。
- 数据分析平台通常需要实时计算、查询并借助可视化平台展示数据。通过数据分析平台,用户可以更加直观、高效和全面地了解数据分布情况,观察数据变化趋势,最终达到数据驱动业务决策的目标。
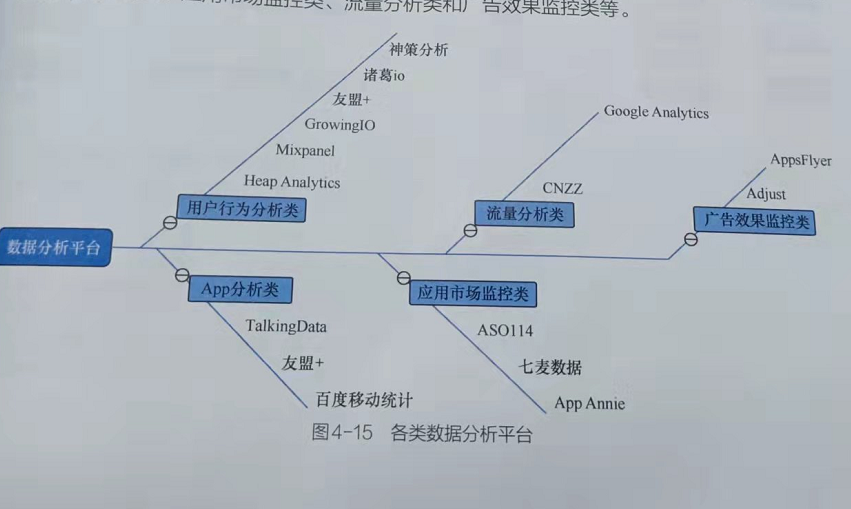
- 与单纯的数据可视化类平台或BI报表相比,数据分析平台的链路更长,除最终的可视化数据展示以外,还包括源头的数据采集;而BI报表通常只是对数据的汇总和查询展示,不涉及数据采集、数据存储等环节。如图4-15所示,根据不同的数据分析类型,数据分析平台可分为如下几类:**用户行为类(应用比较多)**、App分析类、应用市场监控类、流量分析类和广告效果监控类等。
项目背景介绍
- 分析手机App用户数量和交易的某些行为习惯,实现精准营销。类似于购物推荐这种
项目需求分析
- 与传统应用开发相同,在迸行大数据项目开发前,首先要明确项目的需求。用户行为分析平台需要提供多种数据釆集方式,通过对埋点数据的采集、处理、建模和存储,进行深度分析和应用,帮助企业高效获取海量数据,并进行多维、实时和准确的数据分析,还原真实业务场。用户行为分析平台的业务流程包括数据釆集、数据处理、数据建模、数据存储、数据簑理、智能分析和基础看板。图4-16是用户行为分析平台的业务流程。
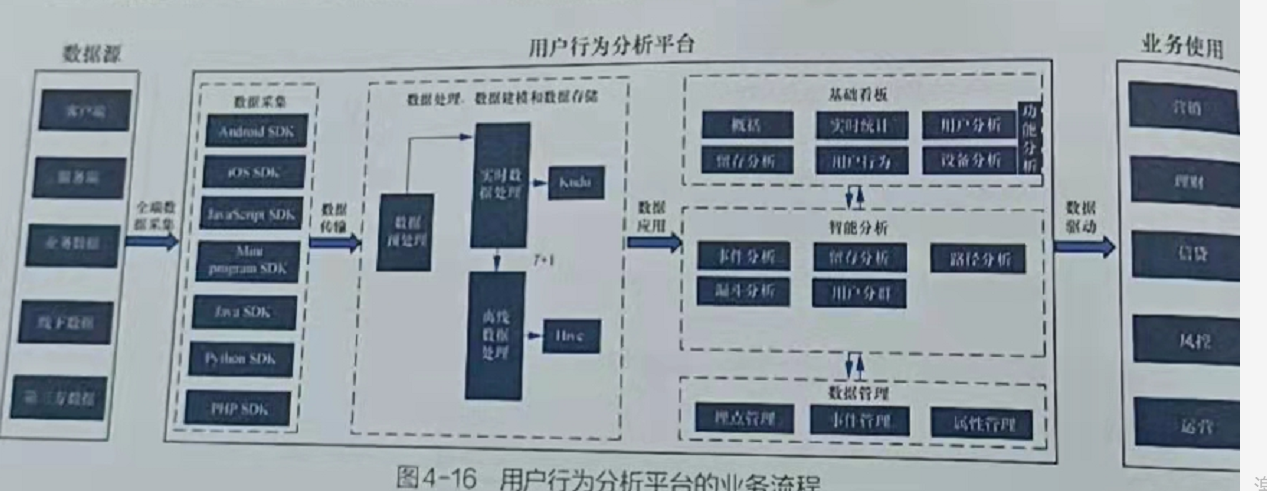
- 用户行为分析主要包括:基础看板和智能分析
- 基础看板:如实时统计在线人数、启动次数
- 智能分析:如从商品浏览率到提交订单,支付订单,各个节点用户转化率
项目开发流程
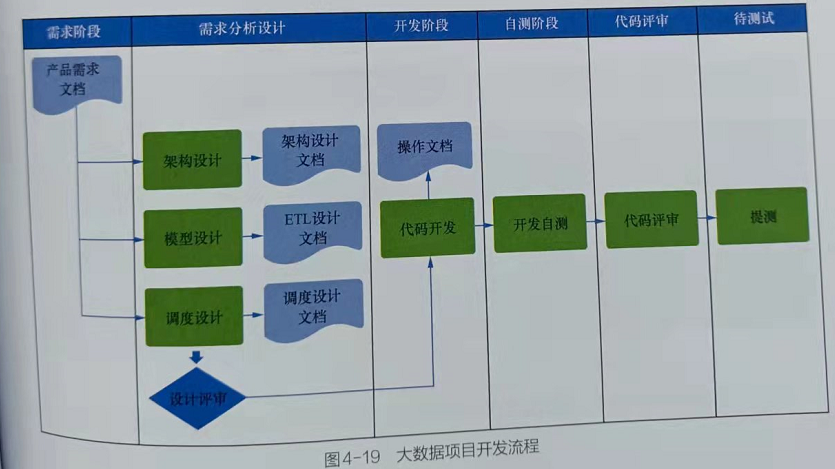
- 大数据项目的完整流程如图4-18所示,在进行大数据项目开发时,首先,大数据开发工程师需要根据产品需求文档进行架构设
计、模型设计和调度设计,产出架构设计文档、ETL设计文档和调度设计文档;然后,项目
相关人员(包括测试人员)需要对这些设计进行评审等。
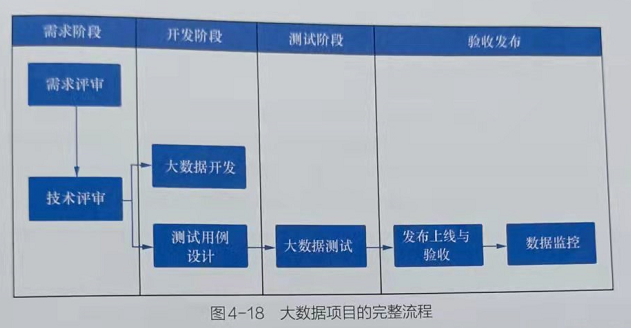
- 图4-19为大数据项目开发流程。
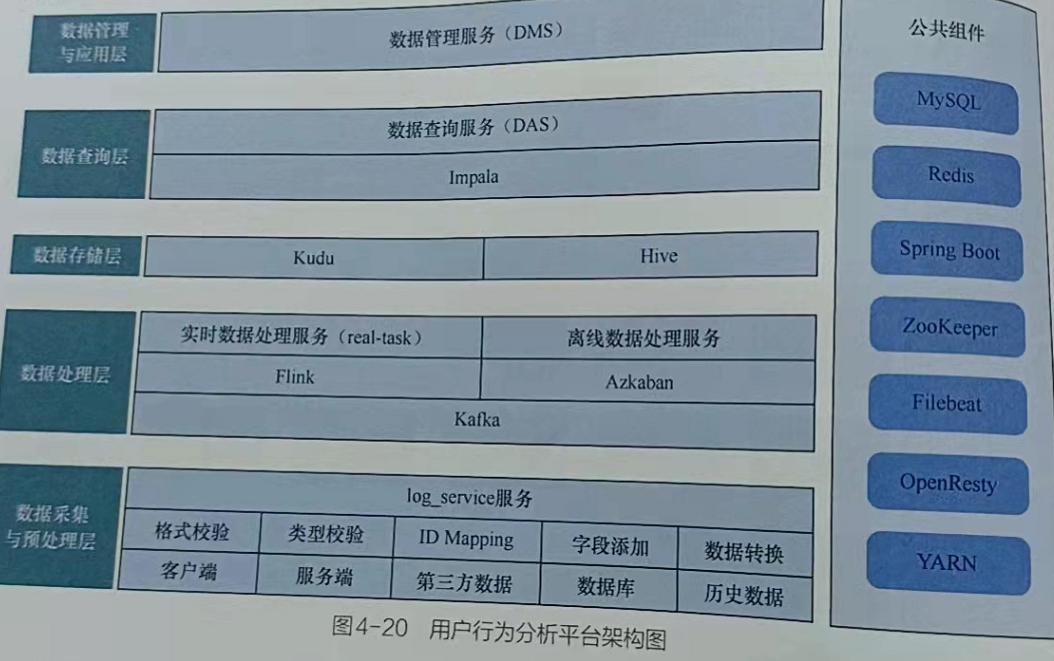
结构设计
根据平台需求的特点,在架构设计时,将用户行为分析平台拆分为4个服务:
- 数据采集与预处理服务( og service)
- 数据处理服务(实时数据处理服务(real-task)使用Flink,离线数据处理服务采用 Azkaban进行任务调度),
- 数据查询服务(DAS),
- 数据管理服务(DMS)
如图4-20所示。数据从源数据到可视化展示需要从下至上经过这些服务的处理。
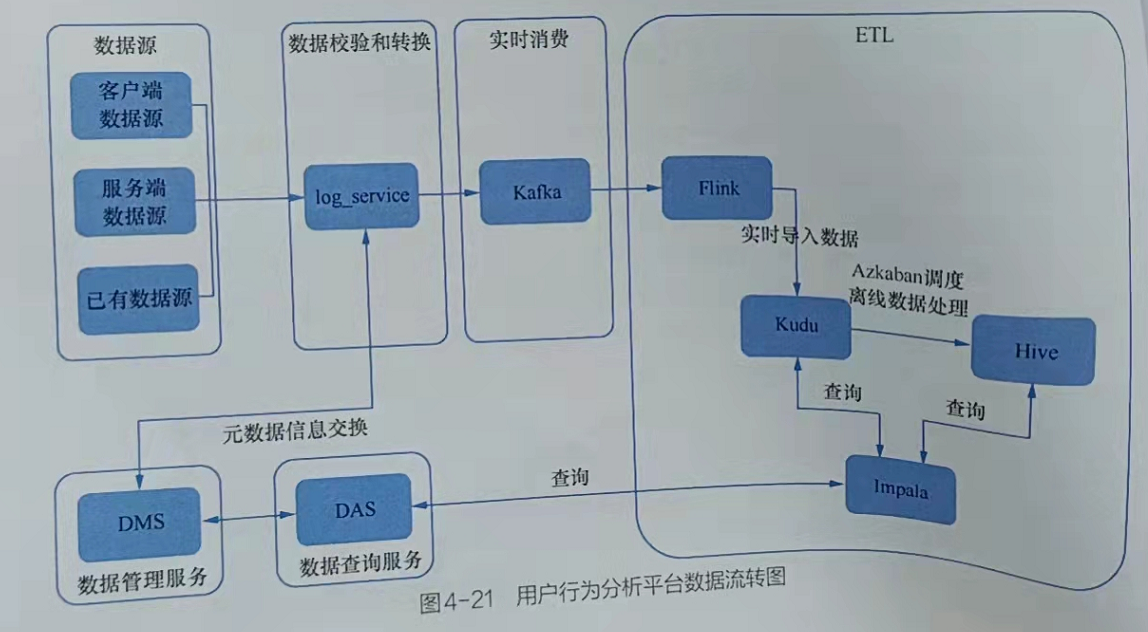
用户行为分析平台的核心是数据处理,即从数据采集到数据应用的数据流转,如图4-21
模型设计
根据用户行为分析平台的功能和特点,我们需要设计能够满足其应用需求的数据仓库架构。图4-24是一个数据仓库架构方案:
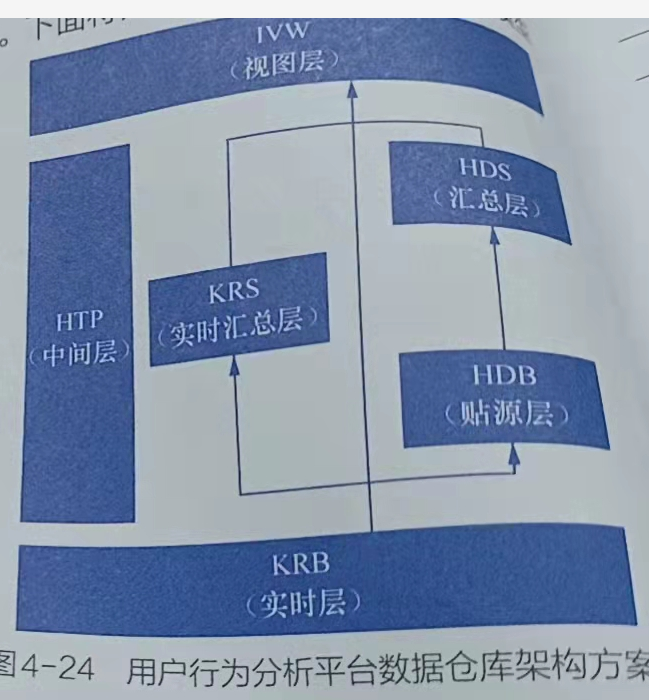
- RB层(实时层)KRB的全称是 Kudu ReaBase,该层的表全部为未统计汇总的实时明细数如 krb. trs_app_event_log表是埋点日志事件表
- KRS层(实时汇总层)KRS的全称是Kucu Real Sum,该层的表全部为统计汇总的实时明细数据,如ks. rs app_user_open_dh表是App用活跃统计表(以小时为单位进行分区)表名的结尾后缀用于表明该表分区间单位,如本例中的dh表示小时进行分区。
- HDB层(贴源层):HDB的全称是 Hive Data Base,该层的表全部为未统计汇总的离线明细数据。该层数据是通过mpaa从KRB层同步过来的,如 hdb db app_equ_install_info表是App安装设备信息表。
- HDS层(汇总层):HDS的全称是 Hive Data stat,该层的表全部为统计汇总的离线数据明细
- HTP层(中间层):HTP的全称是 Hive Temporary,该层的表全部为数据处理过程中生成的中间临时数据,如 htp. tmp skynet user_retention d表是日用户留存分析中间表(以天为单位进行分区)
- IVW层(视图层):IVW的全称是 mpala View,该层的表全部为mpaa操作的视图表,如ⅳ w.trs app_event log表是KRB层(实时层)中提到的 krs. trs app event_log表的视图。
在后续测试案例中,我们会使用实时层中的埋点日志事件表 krb. trs_ app_event_loc
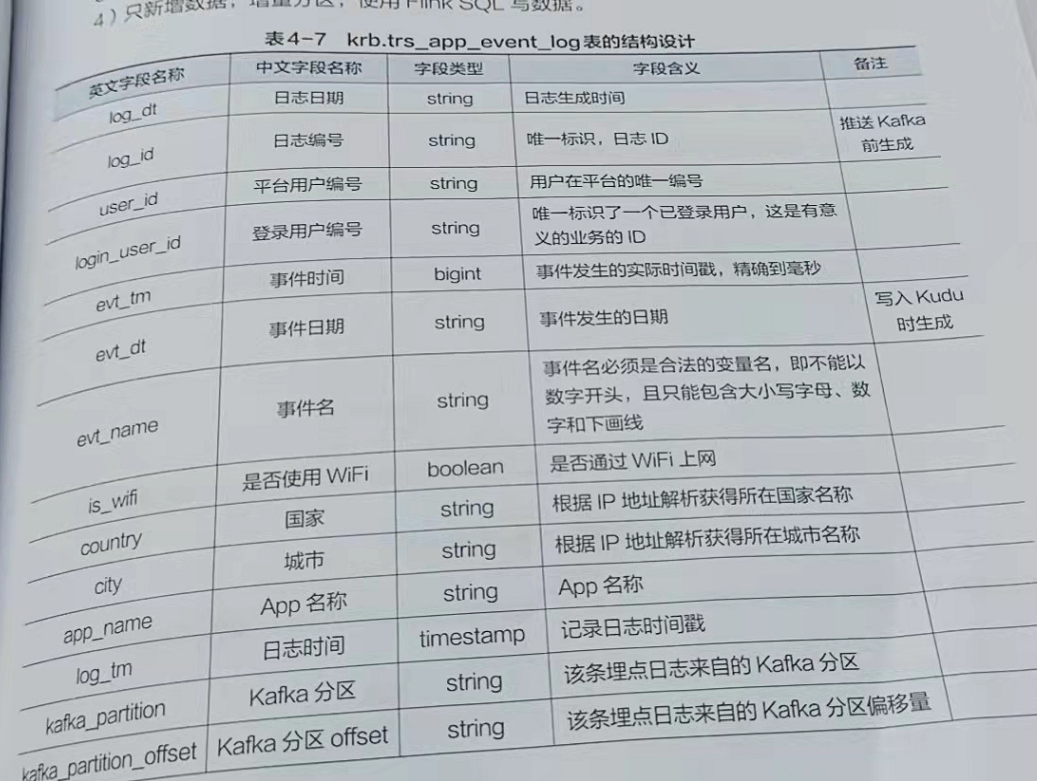
这里只举例说明该表的结构设计。表4-7汇总了(贴出部分)
- 以log_i作为主键。
- 以log_id作为hash分区,以log_dt作为rang分区
- 历史数据分区和最新数据分区一直保留
- 只新增数据,增量分区,使用 Flink SQL写数据
调度设计
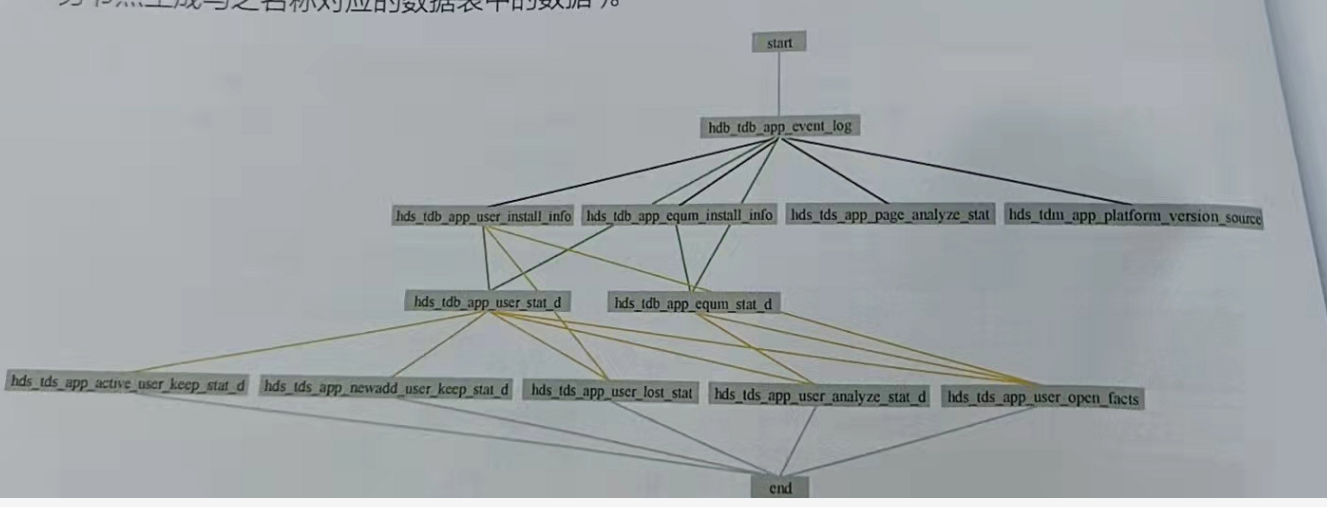
- 上面列出的HDS层数据表位于用户行为分析平台的离线数据存储层。对于离线数据理,具有周期性、重复性的特点,因此,我们使用调度工具 Azkaban提供的可靠计划来处理数据。根据各数据表中数据的前后依赖关系,用户行为分析平台的调度设计如图4-25际示。由图4-25可知,为了提高项目的可读性,子任务节点的命名与表名保持形式上的统一(子任务节点生成与之名称对应的数据表中的数据)。
- 在完成用户行为分析平台的架构设计、模型设计和调度设计后,开发人员便可以根据它们进行相应的代码开发。通过对用户行为分析平台项目的介绍,我们不难发现,项目中需要开发的功能多、业务流程复杂,需要测试人员的参与来保证平台质量。、