需求采集
下面以JForum 论坛为例进行需求采集,首先要了解系统物理架构与逻辑架构。
物理架构:指导进行测试环境建立,测试环境与生产环境的架构趋于一致。
逻辑架构:让我们对系统的逻辑组成有所了解,进行测试时能够清楚地划分问题出现地区域。
系统架构
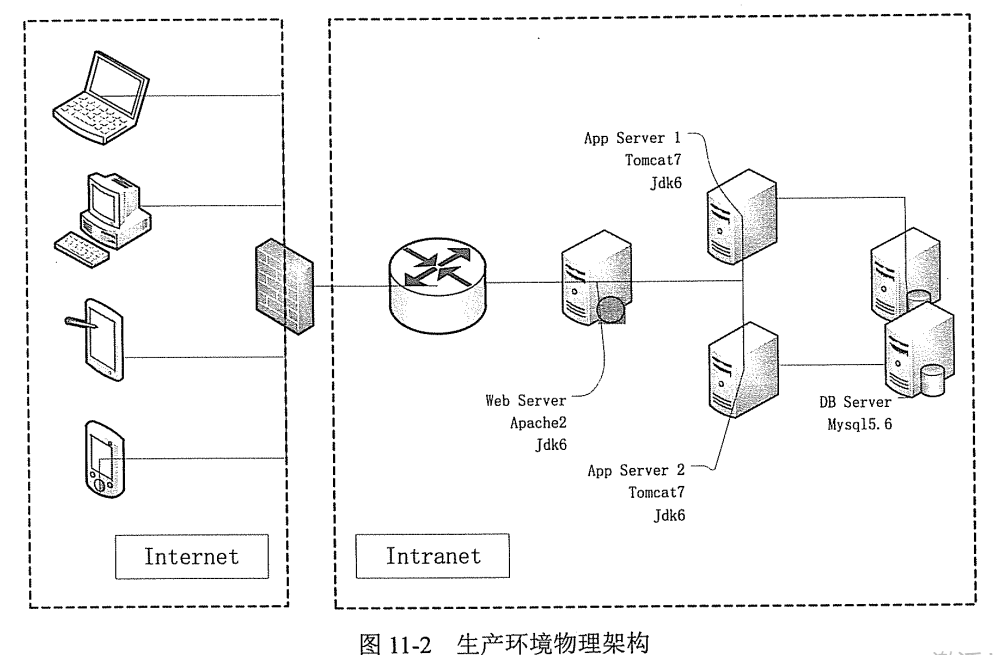
WebServer 负责反向代理,静态请求处理;Tomcat7 负载动态请求处理;Mysql5.6 做双击热备
为了更准确地模拟生产环境负载,在物理架构上尽量保持与生产同步,在机器配置及数量上,可以缩小比例,由测试环境来推算出生产环境的性能。(如何用测试环境准确估算到生产环境,参考TPC-E标准进行评测)
逻辑架构
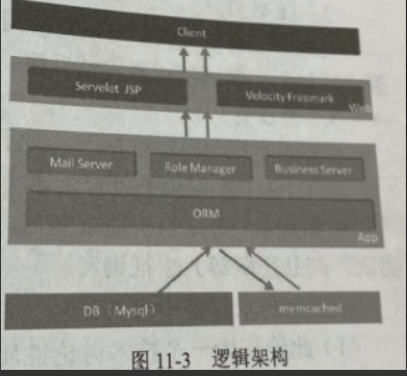
- 逻辑架构:逻辑架构展现的是软件系统中元件之间的关系,比如用户界面、数据库、外部系统结构等。下图是应用服务的逻辑结构,列出了系统服务组件、邮件服务、权限管理、业务服务(对于JForum 就是发帖、回帖、浏览帖子)。Web层是通过 JSP 与 Velocity Freemark 来展现的。
- 通过逻辑架构能迅速了解到系统的主要功能与服务,并且知道其逻辑关系,有助于我们设计测试场景
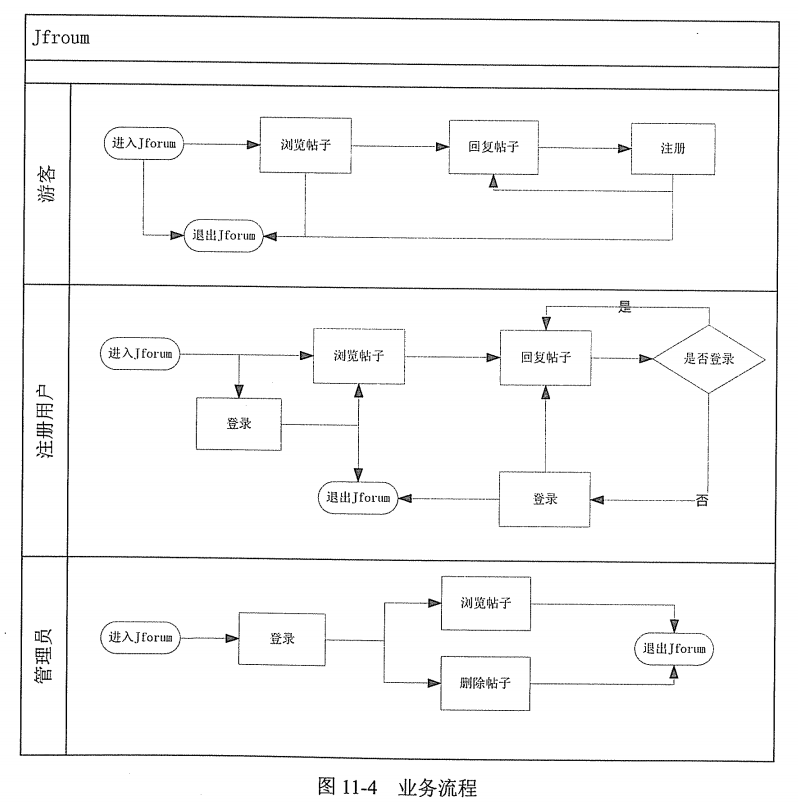
业务流程
- 确定系统的主要业务流程,方便写性能测试用例。
需求文档中性能需求说明:
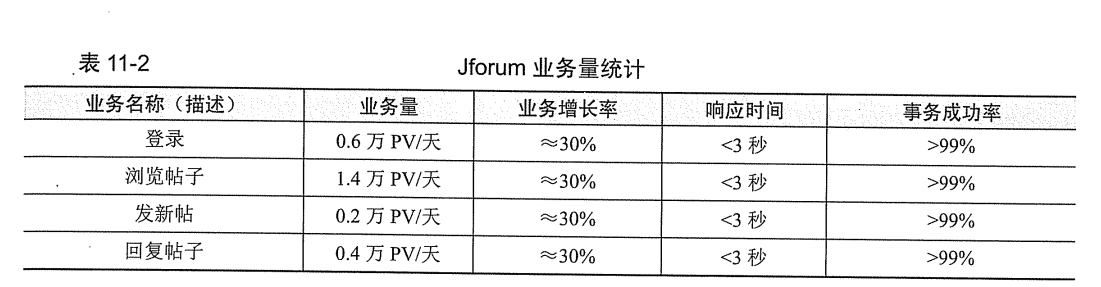
此论坛为一个技术讨论性质的论坛,注册用户规模预计是10万,每日活跃用户数预计为5%,即5000.
用户在论坛中的活动以浏览、发帖及回帖为主,日 PV 预计为 2 万 PV。其中浏览、发帖、回帖比例大约为 7:1:2.
- PV:用户每访问一个页面统计为一个PV。
系统业务增长率为 30%,系统在 3年内不打算进行分库分表处理,需要系统在性能上能够支撑住,也就是测试时需要3年的存量数据。
要求系统能够提供良好的系统体验,比如浏览帖子、发帖、回帖应该控制在3秒内。
为了系统稳定,要求在日常营运时 CPU 使用率<70%,磁盘 Disk ime<70%且无网络瓶颈。
硬件指标
- 系统硬件指标对象是硬件资源,比如CPU、内存、磁盘、网络带宽等。下表列出了主要的性能指标及阈值,这些指标比较抽象,在监控分析时应该进一步细化;比如 CPU的性能指标在 Linux 中分为用户利用率、系统利用率及平均负载等重要指标。

需求分析
- 需求分析的目的是确定性能测试范围,分析出哪些业务纳入性能测试范围及性能指标是什么?另外要分析用户使用行为、业务分布、分析业务量;估算出 TPS与并发用户数等性能测试执行依据。
圈定测试范围
如何圈定测试范围?
(1)确定高频次的业务
(2)确定性能影响大的业务
(3)确定此功能的可验证性。比如使用支付宝来支付商品费用,如果余额不足,会引导选择使用银行卡来支付。这样支付宝会调用银行的接口来完成银行账户的扣减。银行的接口不提供支持时,需要模拟银行网关这个过程,这就是可验证性分析及解决方案,最终采用 Mock程序来配合测试。
明确性能指标
- (1)吞吐量(PV、TPS):
日 PV 是 2 万,3年 30%的增长,日 PV=2*(1+30%)² ≈3.38万
(2)响应时间:要求3秒以内
(3) 成功率:99%以上
(4)稳定波动正常范围
(5)其他各项硬件等性能指标。参照硬件指标
分析业务量
测试数据的多少对测试结果会有影响,特别是数据成千万上亿条后,性能影响明显。
性能测试时,除了需要做足一定数量的历史数据,还得关注业务量的增长。需求中年业务增长率 30%,可以理解成年 PV 也会增加 30%。所以测试时要以第3年的业务量为标准来测试,避免错过积累一定数据后性能变差的情况,把问题提前暴露出来。
计算 TPS
TPS:表示每秒平均事务数。即吞吐量。
上面分析业务量的数据是以PV来统计的,要计算 TPS ,需要把 PV 转化成 TPS。一个 PV即是对服务器的一次请求,把一个请求放在一个事务中来统计服务器的响应耗时,响应完成即是一次事务完成,这么说一个 PV 即是一个事务(PV 并不能直接等同于 TPS,PV代表了一次客户请求,这次请求可能请求了很多信息,比如图片、样式、JS信息等,发新帖时我们通常只关心发帖的动作耗时,并不关心页面刷新时 JS、样式的耗时,此时就把 PV 等同于 TPS);比如一个功能页面(浏览帖子)一秒会有 10 个 PV,那么此功能的 TPS 即为10。
TPS一般要取系统业务高峰期的值,虽然系统不是总处在高峰期,但高峰期 TPS 才能代表系统的实际处理能力。要得到高峰期的 TPS 我们需要分析业务发生时间。
UV:一天之内网站独立访客数(以 Cookie 为依据),一天内同一访客多次访问网站只计算 1 个访客(小于等于 PV)。
回到示例项目Jforum,找出日高峰。下表是高峰日 Jforum 论坛的 PV 数据统计(业务量单位为 PV)。
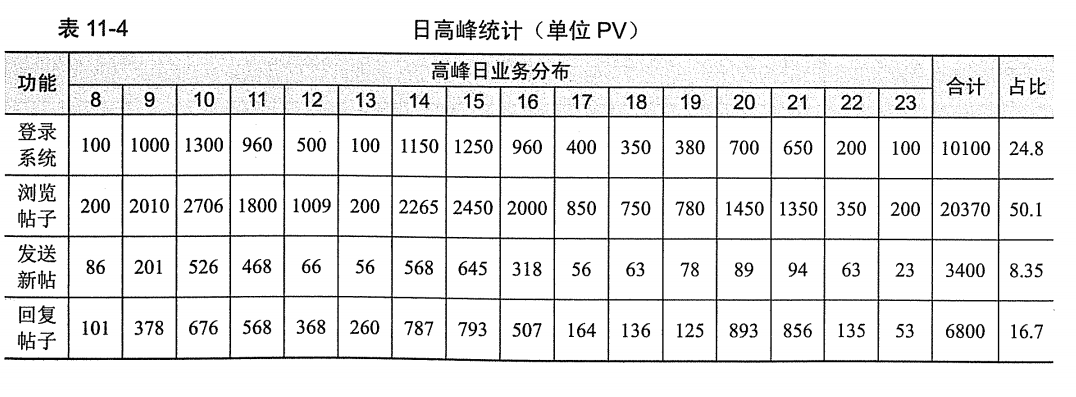
综合看上午十点是访问高峰,PV约为 5208(登录、浏览、回帖、发帖合计),那么这个时段 TPS=5208/3600≈1.45.
这样取平均值是不合适的,一个小时间隔时间太长,采集的业务数据并没有说明在这一个小时中吞吐量是平均的,还需要细分。如果能细分到每分钟的业务量数量,那 TPS 的估算就越准确。
可以采取 80/20 原则来估算,在性能测试中,20%的时间做了 80%的事情。
80/20 原则计算
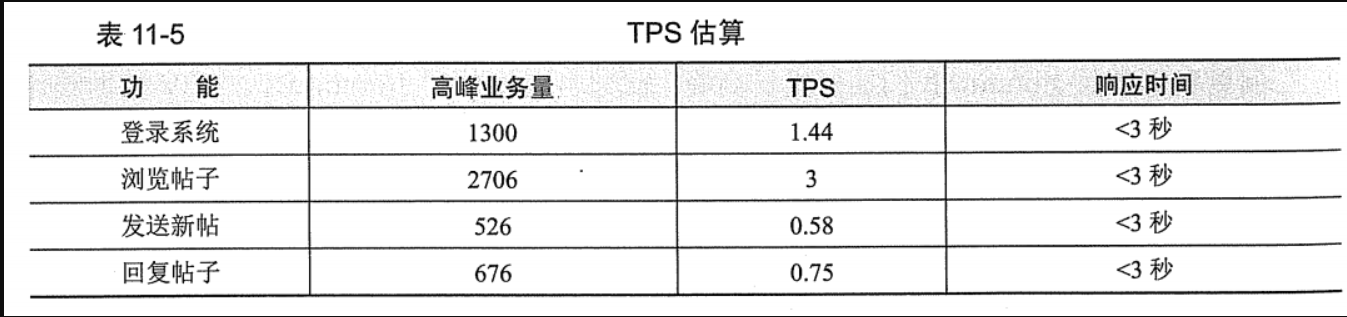
TPS = 5208*80% / (3600*20%) ≈ 5.8,具体如下表- 登录的
tps=1300*0.8/720=1.4444
- 登录的
- tps还可以用来计算并发数
并发数计算
- 三种估算方式:1.tps进行估算(我们采用这种) 2.由在线活动用户数估算 3.根据经验估算
- TPS=事务数/时间,假设所有的事务都来自不同的用户,那么并发数=事务数=tps时间。
- vu=tps*(runtime+thinktime)
- vu表示此业务的虚拟用户数,即并发数
- runtime是测试程序/脚本运行一次所消耗的时间,包含事务时间+非事务时间
- thinktime是模拟用户思考或者填写表单消耗的时间;
- 下图是发帖动作伪代码

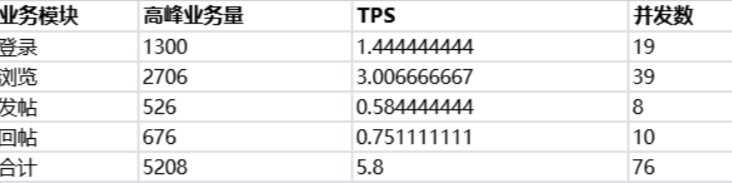
根据公式我们计算一下 Vu,上面计算TPS 为5.8
不包括非事务时间(ThinkTime 与程序消耗时间)情况下计算 VU;
Vu=TPS*T2=5.8*2=12
包括非事务时间情况下计算 VU。
Vu=TPS*(Runtime+ThinkTime)=5.8*(0.2+2+0.2+0.2+0.2+2+0.2+2+2)=53
可以看到两者之间的 Vu 数量相差巨大,如果我们不把 Runtime 与 ThinkTime 加进去,算出来的12个并发用户在测试执行时很有可能无法达到 TPS=5.8 的目标。
业内一般把 Think Time 设为 3 秒,3 秒刚好符合用户在页面的停留平均时间。那么我们巴上面的 Think Time 时间换成3 秒。测试需求中要求响应时间小于3秒,那么我们以3秒为阀值。
VU=TPS*(Runtime+ThinkTime)=5.8*(T1+TT1+T2+T3+T4+T5+TT2+T6+T7)=5.802+3+3+0.2+0.2+0.2+3+3+0.2)=76。由于我们计算并发数,取得是系统的tps(登录,浏览,发帖,回帖),实际计算出来的并发是系统业务的总并发数,如登录的并发数量
1.44*13=18.72向上取值就算19,需要按比例分配到不同的业务中,
本次文章抄录于《6 全栈性能测试修炼宝典JMeter实战》