说明
阅读本章,请把hadoop和hive环境搭建好,可以参考如下文章:
- 第三章 大数据之Hadoop搭建
- 第四章 大数据之hive搭建
- 本次实例来自对《大数据测试技术与实践》中实例补充,书中的实例并不能直接使用,有些地方是错误的,我也修改和补充
数据仓库实例
在本节中,我们通过一个简单的实例介绍数据仓库对数据的处理过程。假设有一家连锁超市,它有多家分店。每一个分店都有很多种类的商品,包括日用品、肉类、冷冻食品、烘焙食品和花卉等。所有产
品在整个连锁超市环境下有一个唯一的产品编号。图3-15为一张顾客结账清单。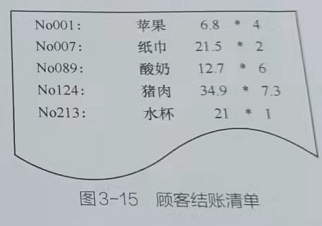
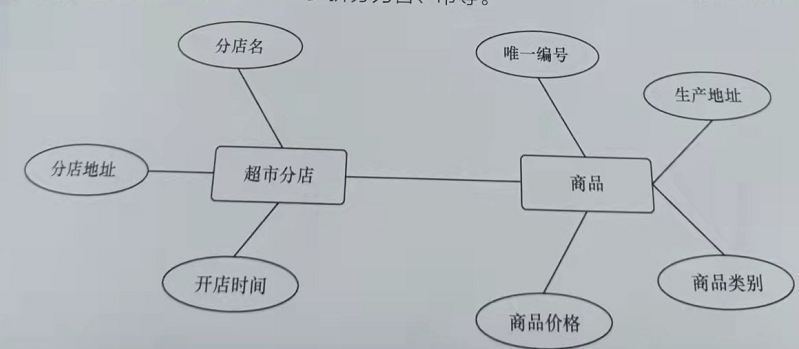
经过一段时间的商品销售后,连锁超市积累了大量销售数据,如下图所示,超市分店具有分店名、分店地址
和开店时间属性,商品有商品类别、商品价格、唯一编号和生产地址属性。当然,地址可以进一步拆分为省、市等。
- 假设对商品A进行促销,如发放代金券、降价等,现在分析促销活动对商品A销售量的,为了简便,本实例统计超市分店中商品A每天的销售量、到店消费人数和购买商品A的消费者的比例
- 我们在数据仓的设计与构建文章中的数据仓库的设计中提到过,数据仓库分为数据接入层、数据明细层、数据汇总层和数据集市等。数据接入层负责将业务系统中的商品相关销售数据导入;数据明细层负责对数据接入层的数据进行预处理,过滤”脏”数据等;数据汇总层将数据按照订单进行汇总;数据集市层负责聚合计算相应的指标。
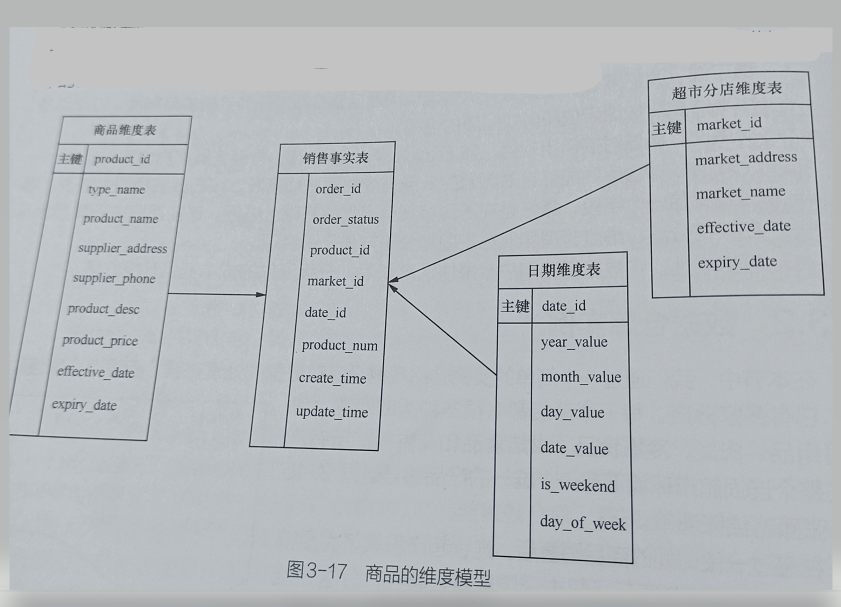
- 由于要对商品在时间、地点等维度的指标进行汇总计算,因此,我们在数据仓库层使用维度建模方式建表,(我们在数据仓的设计与构建中的数据仓库建模方法也说过相应概念)。显然,我们对日期、超市分店(地址)和商品等维度比较感兴趣。图3-17所示为商品的维度模型实际的建模过程比这复杂。以日期维度为例,在实际建模中,时间维度表一般会会有当天是一个月中的哪一天,当天是一年中的哪天,当前周是一年中的哪周,当前季度是年中哪季度,以及时间视计算肭表示等字段,方便将销售指标在各种时间点上进行同比。
假设超市业务系统中的销售数据是以实际购物清单拆分的形式存放,即在购物清单中,含有品、商品价格和交易时间(清单创建时间)等信息,则超市业务系统的数据库中会有如图下的表关系
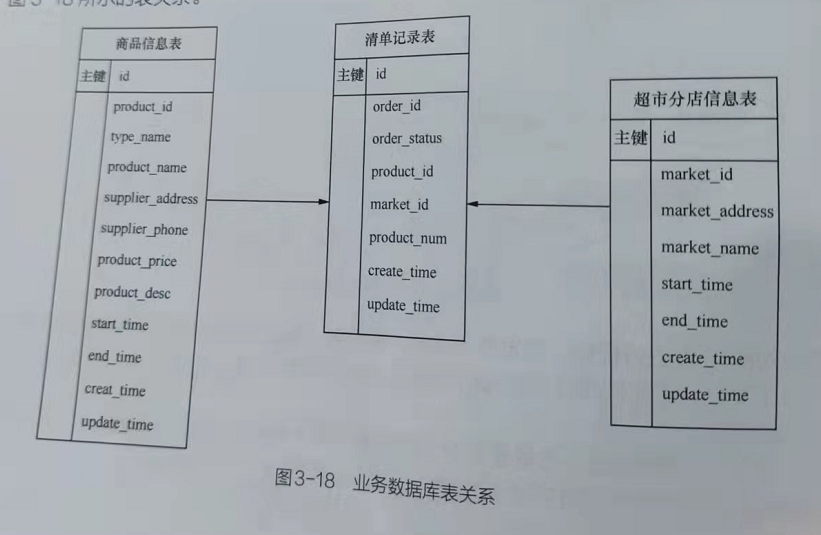
由于商品信息表和超市分店信息表的数据量不大,且基本无改动,因此可以选择全量更新的方式将数据加载到数据仓库。而来自各超市分店的商品销售清单的数据量很大,且每天会有新插入的数据记录,因此,在将数据加载到数据仓库时,可以选择增量加载方式
在本实例中,对于数据仓库的存储,采用HDFS和Hive,在ETL过程中,使用 HiveQL。图3-19为各级数据表的关系。
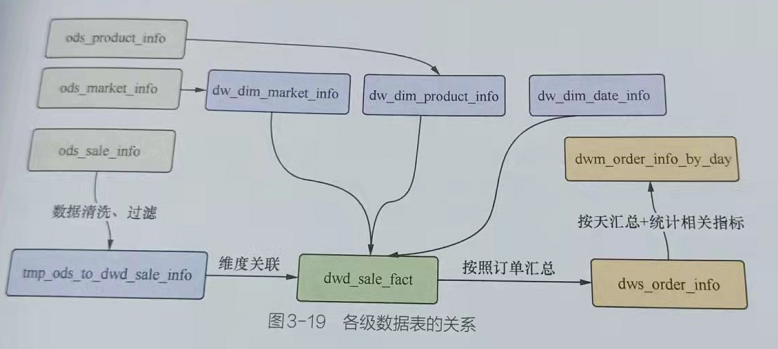
数据接入层ODS
创建接入层的表
首先,在Hive中,创建数据库接入层对应的表,代码如下:
1 | # 切换到hadoop用户 |
准备业务数据
批量造mysql表的数据,采用存储过程的方式
mysql中创建业务关系表,product_info(商品信息表)、market_info(超市分店信息表)、sale_info(清单记录表)
1 | mysql -uroot -p |
插入数据
超市分店
1 | mysql -uroot -p |
商品表-存储过程
1 | mysql -uroot -p |
- 数据列表
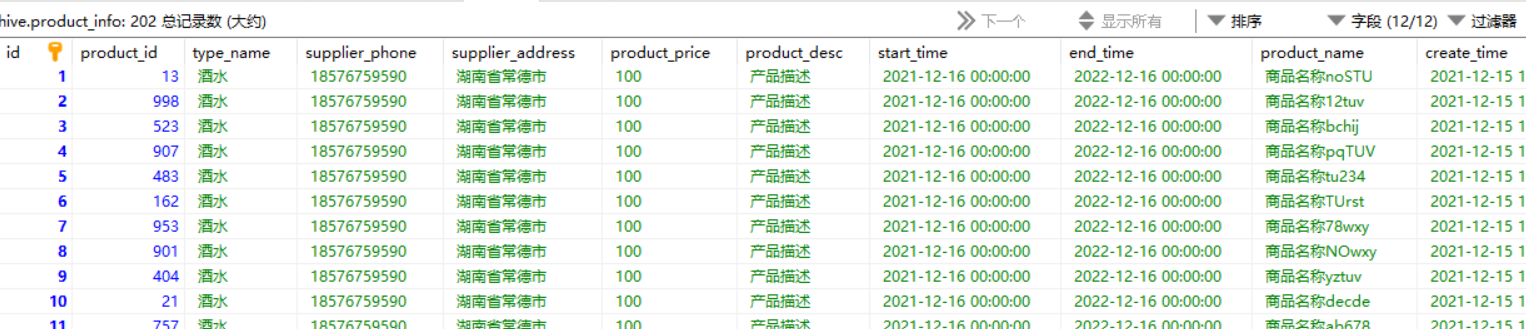
清单记录表-存储过程
1 | mysql -uroot -p |
- 数据列表如下
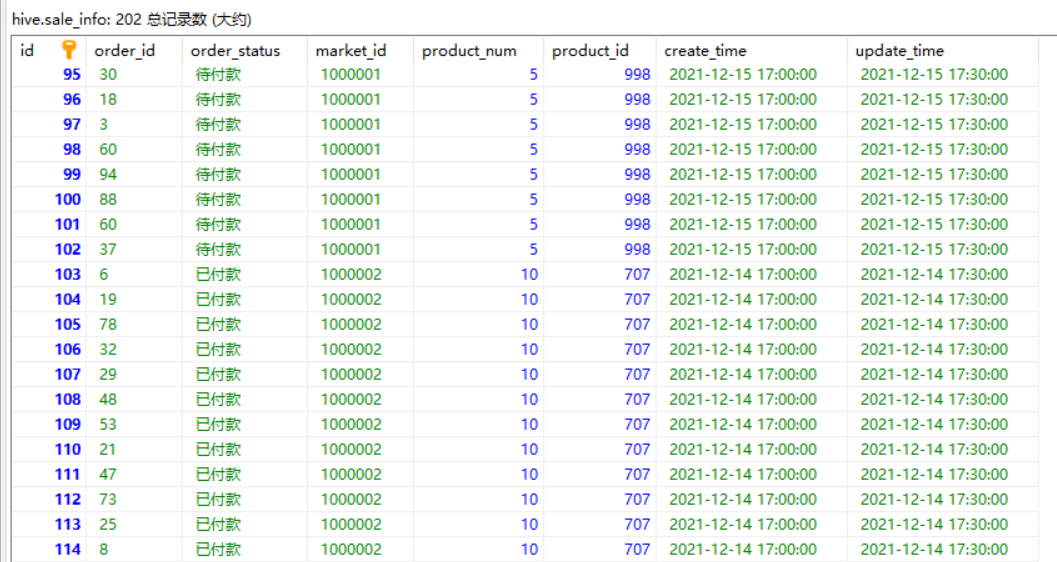
业务数据导入ODS-datax
datax 环境搭建
- 建议自己用源代码编译方式,比较稳妥
- 下载源文件解压
1 | wget https://github.com/alibaba/DataX/archive/master.zip |
- 下载maven
1 | sudo wget --no-check-certificate https://dlcdn.apache.org/maven/maven-3/3.8.4/binaries/apache-maven-3.8.4-bin.tar.gz |
- 配置maven本地仓库, 进如本地maven安装目录里的conf目录,
vi settings.xml进行如下修改
1 | -- 设置仓库地址 |
- 最后查看maven安装结果 maven -version
1 | [root@VM-24-13-centos resp]# mvn -version |
- 修改datax的目录中的pom.xml中的内容
1 | <mysql.driver.version>8.0.26</mysql.driver.version> |
- hdfswrite目录下面的pom.xml修改hive和hadoop版本
1 | <properties> |
- 在 datax的目录执行编译命令
1 | mvn -U clean package assembly:assembly -Dmaven.test.skip=true |
- 把target目录中的datax.tar.gz移动到指定目录,解压
1 | [root@VM-24-13-centos target]# cp datax.tar.gz /usr/local/ |
数据超市导入ods表
创建分区信息,手动创建分区路径
不过奇怪的是我用下面命令的方式创建,用datax导入报错找不到创建的分区
1
hdfs dfs -mkdir -p /user/hive/warehouse/hive.db/ods_market_info/dt=2021-12-21
- 用sql原生语句insert插入一条数据后,重新datax导入就成功了
1
insert into ods_market_info partition(dt = '2021-12-21')
1 | # 切换用户 |
- 查看到分区信息
1 | [hadoop@VM-24-13-centos root]$ hadoop fs -ls /user/hive/warehouse/hive.db/ods_market_info/ |
在datax的job目录编写一个mysql_hive_ods_market_info.json文件,同步超市分店配置用
1
2[root@VM-24-13-centos job]# ls
job.json mysql_hive_ods_market_info.json编辑mysql_hive_ods_market_info.json文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"market_id",
"market_address",
"start_time",
"end_time",
"market_name",
"create_time",
"update_time"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://localhost:3306/hive"
],
"table": [
"market_info"
]
}
],
"password": "hive1234",
"username": "hive"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://localhost:9000",
"fileType": "text",
"path": "/user/hive/warehouse/hive.db/ods_market_info/dt=2021-12-21",
"fileName": "ods_market_info",
"column": [{
"name": "market_id",
"type": "string"
},
{
"name": "market_address",
"type": "string"
},
{
"name": "start_time",
"type": "string"
},
{
"name": "end_time",
"type": "string"
},
{
"name": "market_name",
"type": "string"
},
{
"name": "create_time",
"type": "string"
},
{
"name": "update_time",
"type": "string"
}
],
"writeMode": "append",
"fieldDelimiter": "\t",
}
}
}]
}
}hive> show create table hive.ods_market_info;
…..
LOCATION
‘hdfs://localhost:9000/user/hive/warehouse/hive.db/ods_market_info’
….执行命令后在结果中可以看到LOCATOIN,就是hive在hdfs中的存储目录。填写到writer下的path中,dt就是刚刚创建的分区
运行datax命令
1 | # 回到root用户 |
- 查看hive中的超市表中是否有数据
1 |
|
商品信息导入ods表
1 | # 切换用户 |
- 查看到分区信息
1 | [hadoop@VM-24-13-centos root]$ hadoop fs -ls /user/hive/warehouse/hive.db/ods_product_info/ |
在datax的job目录编写一个mysql_hive_ods_product_info.json文件,同步超市分店配置用
1
2
3
4[root@VM-24-13-centos job]# ls
-rwxrwxrwx 1 root root 1587 Dec 21 18:05 job.json
-rw-r--r-- 1 root root 1861 Dec 22 15:54 mysql_hive_ods_market_info.json
-rw-r--r-- 1 root root 1861 Dec 23 09:36 mysql_hive_ods_product_info.json编辑mysql_hive_ods_productinfo.json文件
1 | { |
- 运行datax命令
1 | # 回到root用户 |
- 查看hive中的商品表中是否有数据
1 | su hadoop |
销售事实导入ods表
1 | 切换用户 |
- 查看到分区信息
1 | [hadoop@VM-24-13-centos root]$ hadoop fs -ls /user/hive/warehouse/hive.db/ods_sale_info/ |
在datax的job目录编写一个mysql_hive_ods_sale_info.json文件,同步销售事实表配置用
1
2
3
4
5
6[root@VM-24-13-centos job]# ls
-rwxrwxrwx 1 root root 1587 Dec 21 18:05 job.json
-rw-r--r-- 1 root root 1861 Dec 22 15:54 mysql_hive_ods_market_info.json
-rw-r--r-- 1 root root 2267 Dec 23 10:28 mysql_hive_ods_product_info.json
-rw-r--r-- 1 root root 2267 Dec 23 11:06 mysql_hive_ods_sale_info.json编辑mysql_hive_ods_productinfo.json文件
1 | { |
- 运行datax
1 | # 回到root用户 |
- 查看hive中的销售事实表是否有数据
1 | su hadoop |
- 再次导入一次数据,造成重复的脏数据,为下一步数据清洗例子做准备
1 | [root@VM-24-13-centos bin]# python datax.py -p "-DHADOOP_USER_NAME=hadoop" ../job/mysql_hive_ods_sale_info.json |
- 查看 hive中的销售事实表存在了404条数据,有一半重复的
1 | su hadoop |
数据清洗
- 在业务数据导入到ods层时,可能一些误操作,脏数据等,需要对ods层的数据进行清洗处理,本次就以ods_sale_info表中去重重复的order_id
1 | su hadoop |
数据明细层DWD
- 数据清洗完毕后,把ODS层数据导入到OWD层
数据仓库建模
- 在数据仓库层,采用星形模式创建超市分店维度表、商品维度表、日期维度表和销售事实表
维度建模
1 | # 切换到hadoop用户 |
导入ODS层数据
- 把数据接入层(ODS)导入到维度表中
日期维度表
- 初始化一些测试数据,注意date_value这个字段的值,需要和
tmp_ods_to_dwd_sale_info中的create_time有关联关系,要造一些相等条件的数据
1 | su hadoop |
超市维度表
- ods_market_info 表数据插入
- 此次实例中,好像没有用到
1 | hive>insert into dw_dim_market_info partition(dt = '2021-12-21') select market_id,market_address,market_name,start_time as effective_date,end_time as expiry_date |
商品维度表
- ods_product_info表数据插入
- 此次实例中,好像没有用到
1 | hive>insert into dw_dim_product_info partition(dt = '2021-12-21') select product_id,product_name,type_name,supplier_phone,supplier_address,product_price,product_desc,start_time as effective_date,end_time as expiry_date |
销售事实表
tmp_ods_to_dwd_sale_info表是上述处理重复销售清单记录表的过滤后的临时表
1 | hive>insert into dwd_sale_fact partition(dt = '2021-12-21') select a.order_id,a.order_status,a.market_id,b.date_id,a.product_num,a.product_id,a.create_time,a.update_time |
数据汇总层DWS
- 由于我们要统计商品A的销售量,以及商品A的购买比例,因此在数据汇总层,对销售数据按照清单号进行汇总,并添加include_product_a 字段,用于表示该清单是否商品A(本实例中的商品id为221),处理过程如下:
1 | -- 创建DWS层清单记录表 |
- 参考Hive中case when的两种语法
- 参考hive中对多行进行合
- 发现个奇怪问题,插入的字段居然要和表中的顺序一致,不然为空,比如
product_info就有这样的问题
数据集市层DWM
- 在数据集市层,需要对相关指标进行聚合计算,处理过程如下。
- 此处商品A的id为221
1 | drop table if exists dwn_order_info_by_day; |
总结
- 以上就是数据从数据源经过ETL处理最终加载到数据仓库的整个过程。在实际业务过程中,数据规模庞大、业务逻辑复杂,需要生成大量的ETL处理任务,因此在数据仓库设计过程中,需要考虑中间层数据的通用性。在调度系统(如Airflow、Azkaban等)的调度下,这些ETL任务分批有序执行,最终生成报表等应用所需的数据