playwright
优点
Selenium需要通过WebDriver操作浏览器;Playwright通过开发者工具与浏览器交互,安装简洁,不需要安装各种Driver。
Playwright几乎支持所有语言,且不依赖于各种Driver,通过调用内置浏览器所以启动速度更快。
Selenium基于HTTP协议(单向通讯),Playwright基于Websocket(双向通讯)可自动获取浏览器实际情况。
比如使用selenium时,操作元素需要对每个元素进行智能查询等待等,而Playwright为自动等待:
- 等待元素出现(定位元素时,自动等待30s,时间可以自定义,单位毫秒)
- 等待事件发生
Playwright速度比selenium快很多,还支持异步方式
支持使用API的方式发送请求
限制
- 不支持旧版Edge和IE11。Playwright不支持传统的Microsoft Edge或IE11,支持新的Microsoft Edge (在Chromium上)。
- 在真实移动设备上测试: Playwright使用桌面浏览器来模拟移动设备。
安装
1 | #升级pip |
测试
- 录制代码,输入下面的命令,启动一个浏览器,一个代码记录器,然后再浏览器的所有步骤都自动记录到了代码记录器中
1 | python -m playwright codegen |
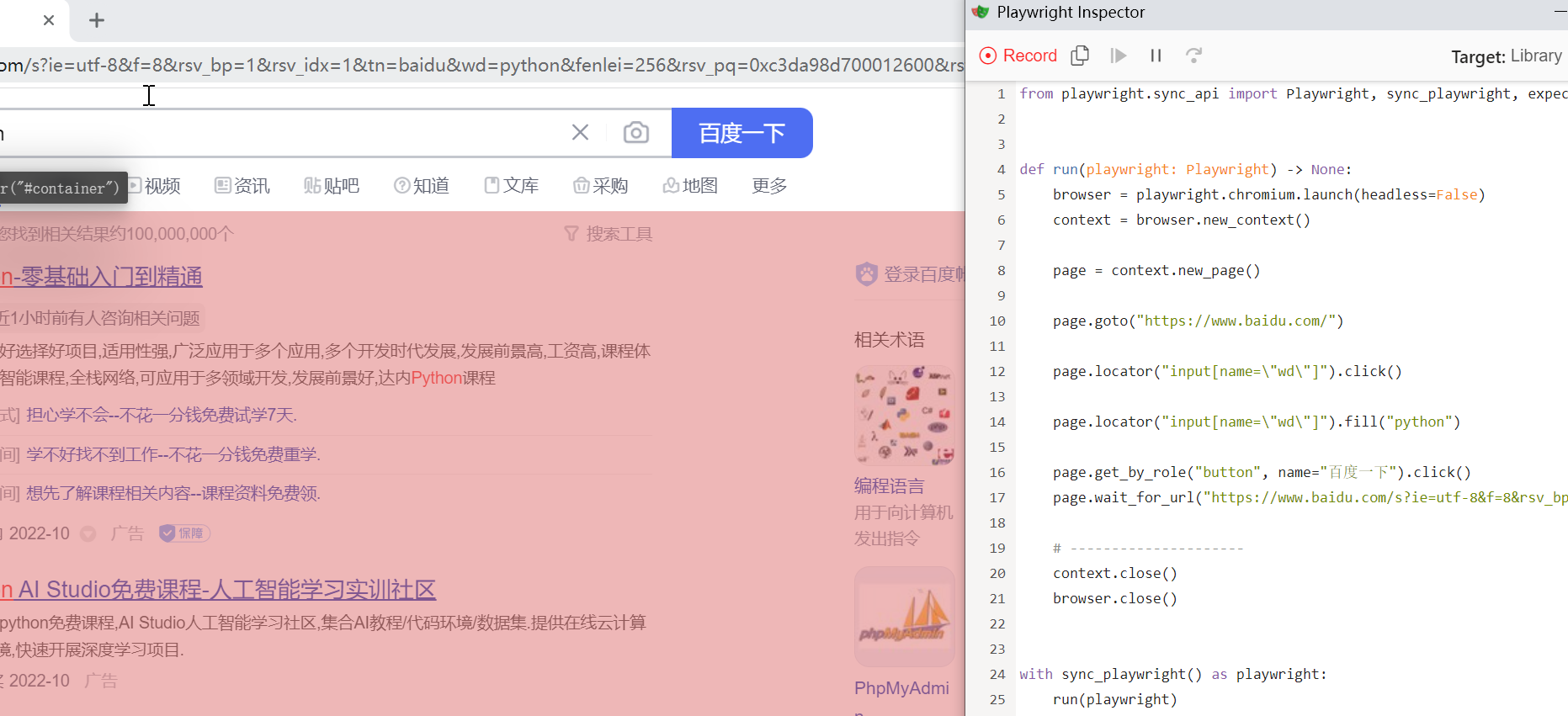
- 录制代码如下
1 | from playwright.sync_api import Playwright, sync_playwright, expect |
通过以上代码可以了解到:
playwright支持同步和异步两种使用方法
不需要为每个浏览器下载webdriver
相比selenium多了一层context抽象
支持无头浏览器,且较为推荐(headless默认值为True)
可以使用传统定位方式(CSS,XPATH等),也有自定义的新的定位方式(如文字定位)
没有使用selenium的先定位元素,再进行操作的方式,而是在操作方法中传入了元素定位,定位和操作同时进行(其实也playwright也提供了单独的定位方法,作为可选)
很多方法使用了with的上下文语法
当然更多的人愿意在Pycharm中手写用例
playwright基本概念
- 来做这里
PlayWright的核心概念包括:
- Browser
- Browser contexts
- Pages and frames
- Selectors
- Auto-waiting
- Execution contexts: Playwright and Browser
- Evaluation Argument
Browser
- 一个Browser是一个Chromium, Firefox 或 WebKit(plarywright支持的三种浏览器)的实例plarywright脚本通常以启动浏览器实例开始,以关闭浏览器结束。浏览器实例可以在headless(没有 GUI)或head模式下启动。Browser实例创建:
1 | from playwright.sync_api import sync_playwright |
- 启动browser实例是比较耗费资源的,plarywright做的就是如何通过一个browser实例最大化多个BrowserContext的性能。
- API:Browser
BrowserContext
一个BrowserContex就像是一个独立的匿名模式会话(session),非常轻量,但是又完全隔离。
(译者注:每个browser实例可有多个BrowserContex,且完全隔离。比如可以在两个BrowserContext中登录两个不同的账号,也可以在两个 context 中使用不同的代理。 )
context创建:
1 | browser = playwright.chromium.launch() |
- context还可用于模拟涉及移动设备、权限、区域设置和配色方案的多页面场景,如移动端context创建:
1 | from playwright.sync_api import sync_playwright |
API:
Page 和 Frame
- 一个BrowserContext可以有多个page,每个page代表一个tab或者一个弹窗。page用于导航到URL并与page内的内容交互。创建page:
1 | page = context.new_page() |
- 一个page可以有多个frame对象,但只有一个主frame,所有page-level的操作(比如click),都是作用在主frame上的。page的其他frame会打上
iframeHTML标签,这些frame可以在内部操作实现访问。
1 | # 通过name属性获取frame |
- 在录制模式下,会自动识别是否是frame内的操作,不好定位frame时,那么可以使用录制模式来找。
API:
Selector
playwright可以通过 CSS selector, XPath selector, HTML 属性(比如
id,data-test-id)或者是文本内容定位元素。除了xpath selector外,所有selector默认都是指向shadow DOM,如果要指向常规DOM,可使用*:light。不过通常不需要。
1 | # Using data-test-id= selector engine |
详细:
Element selectors | Playwright Python
Auto-waiting
playwright在执行操作之前对元素执行一系列可操作性检查,以确保这些行动按预期运行。它会自动等待(auto-wait)所有相关检查通过,然后才执行请求的操作。如果所需的检查未在给定的范围内通过timeout,则操作将失败并显示TimeoutError
如 page.click(selector, **kwargs) 和 page.fill(selector, value, **kwargs) 这样的操作会执行auto-wait ,等待元素变成可见(visible)和 可操作( actionable)。例如,click将会:
等待selectorx选定元素出现在 DOM 中
待它变得可见(visible):有非空的边界框且没有
visibility:hidden等待它停止移动:例如,等待 css 过渡(css transition)完成
将元素滚动到视图中
等待它在动作点接收点事件:例如,等待元素不被其他元素遮挡
如果在上述任何检查期间元素被分离,则重试
1 | # Playwright waits for #search element to be in the DOM |
Execution context
- API page.evaluate(expression, **kwargs) 可以用来运行web页面中的 JavaScript函数,并将结果返回到plarywright环境中。浏览器的全局变量,如
window和document,可用于evaluate。
1 | href = page.evaluate('() => document.location.href') |
Evaluation Argument
- page.evaluate(expression, **kwargs) 方法接收单个可选参数。此参数可以是Serializable值和JSHandle或ElementHandle实例的混合。句柄会自动转换为它们所代表的值
1 | result = page.evaluate("([x, y]) => Promise.resolve(x * y)", [7, 8]) |
结合pytest
- testcas\conftest.py
1 | import pytest |
- testcase\test1.py,
page.request.get可以直接发送请求
1 | import pytest |
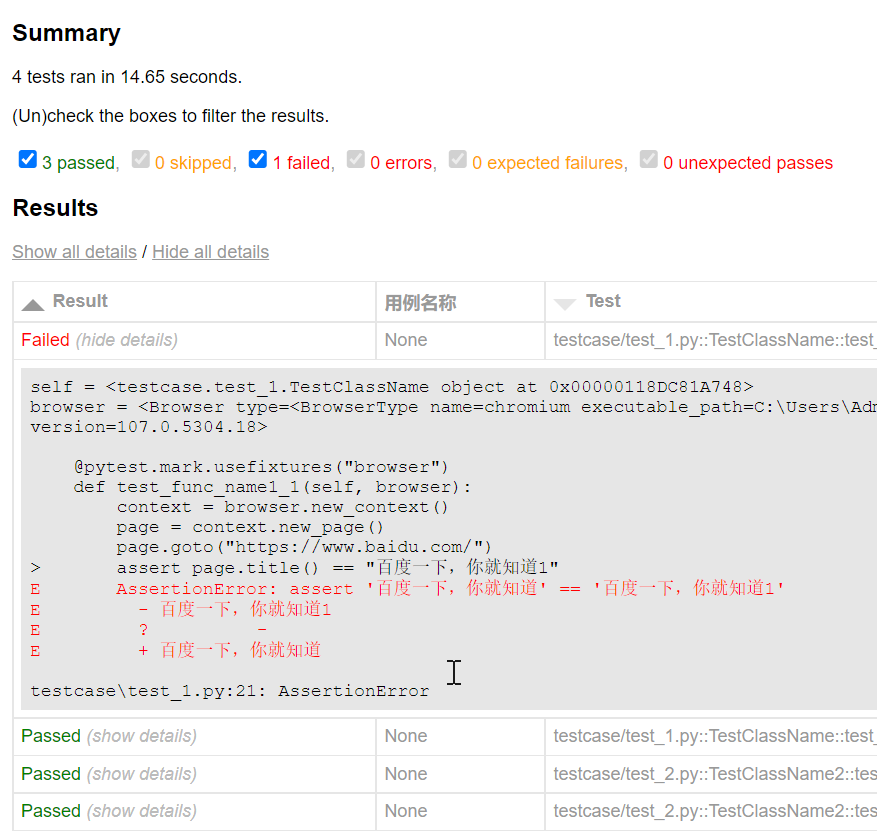
- 执行用例
1 | # 批量运行用例 |
- 查看执行结果
检查元素可见性
- 在元素定位过程中,经常出现元素出现了,但是实际定位不到,这时候可以检查dom元素的可见性
1 | def find_el(page, el, timeout=10000): |
其他
- 如何集成到CI上待实践
- 关于多机并行,可以多进程去启动,也可以在CI上新建几个节点去执行