1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
| import re
import urllib.request
import requests
from bs4 import BeautifulSoup
import os
import time
from Threads import BaseThread
PATH = lambda p: os.path.abspath(
os.path.join(os.path.dirname(__file__), p)
)
'''
https://music.163.com/playlist?id= 得到播放列表
http://music.163.com/song/media/outer/url?id= 得到下载链接
urllib.request.urlretrieve 把远程下载的mp3文件下载到本地
'''
class Music163:
def __init__(self):
pass
def get_music_163(self, id):
user_agent = 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 ' \
'Safari/537.36 '
headers = {'User-Agent': user_agent}
data = requests.get("https://music.163.com/playlist?id=" + id, headers).text
soup = BeautifulSoup(data, 'lxml')
temp = []
for i in soup.find("ul", {"class", "f-hide"}).find_all("a"):
pattern = re.compile('<a .*?id=(.*?)">(.*?)</a>', re.S)
items = re.findall(pattern, str(i))
temp.append([items[0][0], items[0][1]])
return temp
# 批量下载
def download(self, value):
for i in value:
if os.path.isfile(PATH("mp3/" + i[1] + ".mp3")):
print("%s已经被下载了" % i[1])
else:
url = 'http://music.163.com/song/media/outer/url?id=' + i[0] + '.mp3'
urllib.request.urlretrieve(url, '%s' % PATH("mp3/" + i[1] + ".mp3"))
print("%s下载成功" % i[1])
# 单个下载
def get(self, value):
if os.path.isfile(PATH("mp3/" + value[1] + ".mp3")):
print("%s已经被下载了" % value[1])
else:
url = 'http://music.163.com/song/media/outer/url?id=' + value[0] + '.mp3'
urllib.request.urlretrieve(url, '%s' % PATH("mp3/" + value[1] + ".mp3"))
print("%s下载成功" % value[1])
# 多线程
def multi_thread():
id = "2786226719" # 播放的列表id
start_time = time.time()
threads = []
mc = Music163()
data = mc.get_music_163(id)
count = len(data)
for i in range(0, count):
threads.append(BaseThread(mc.get(data[i])))
for j in range(0, count):
threads[j].start()
for k in range(0, count):
threads[k].join()
end_time = time.time()
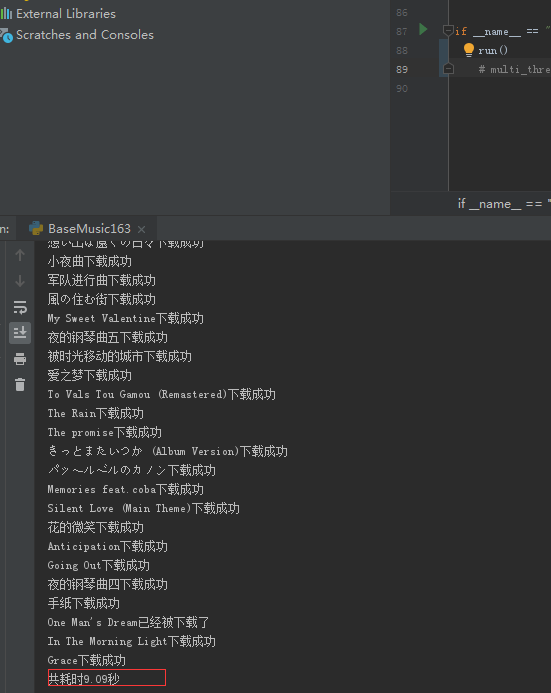
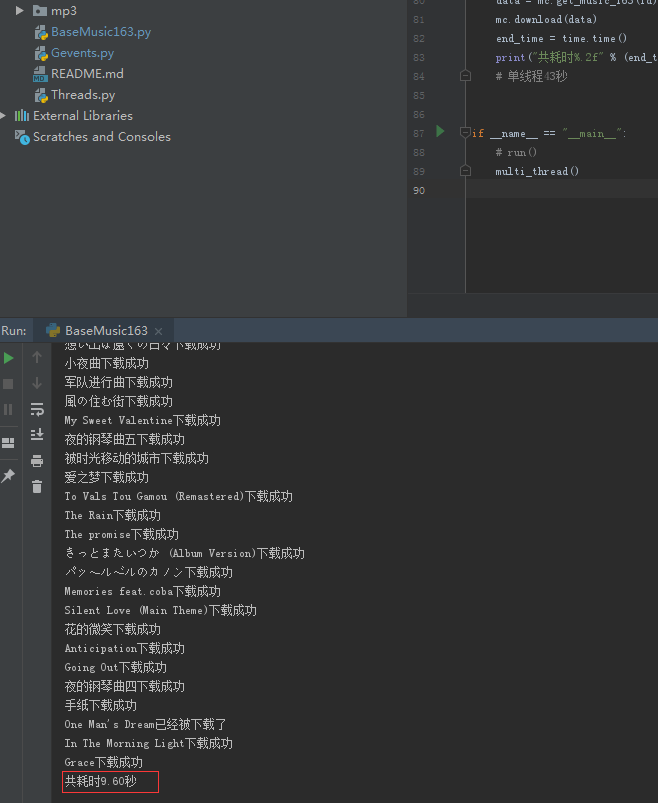
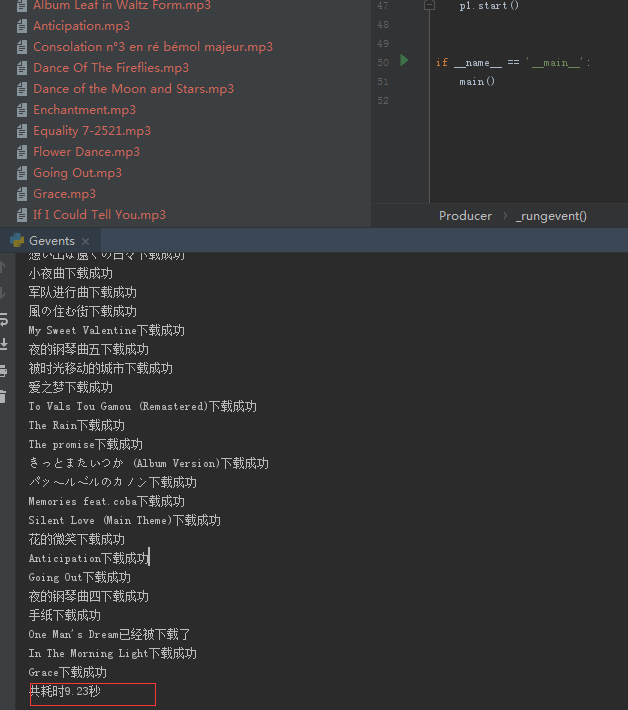
print("共耗时%.2f" % (end_time - start_time) + "秒")
# 多线程47秒
# 运行单线程
def run():
id = "2786226719" # 播放的列表id
start_time = time.time()
mc = Music163()
data = mc.get_music_163(id)
mc.download(data)
end_time = time.time()
print("共耗时%.2f" % (end_time - start_time) + "秒")
# 单线程43秒
if __name__ == "__main__":
# run()
multi_thread()
|